Category
Industrial Artificial Intelligence, Defined

Last updated: May 2026
The most expensive industrial AI project is the one that demos beautifully in a boardroom and never makes it near the line, because the slide deck never had to read a real sensor, satisfy a safety officer, or survive a network that was wired before the model existed. That gap, between a convincing pilot and a system in production, is what the phrase industrial AI is really about. Arkeo AI was founded in 2023 on 25 years of business operating experience and three years of deploying agents in production, and the honest pattern from running these systems is this: industrial AI lives or dies on the data path, the approval logic, and a named owner, not on the model. In Arkeo's deployments the early weeks go to wiring and validating one MES, SCADA, ERP, or historian feed before the first production-grade model call, defining who has to approve a consequential action, and naming the person accountable for the system after the demo ends. The model is the easy part. The plant context around it is where the work and the risk sit. The U.S. government's own playbook for this, the NIST AI Risk Management Framework, treats validity, safety, and security as foundational to a trustworthy system, which is exactly the bar a plant-floor deployment has to clear before it earns a place near production.
This guide is the systems definition, not a glossary entry. If you want that same lens applied to your own operation, you can book a free AI Assessment and get a read on which workflows are worth automating and what architecture they need, but the rest of this page gives you the framework either way. For the broader use-case picture, this sits inside the larger guide to AI in manufacturing.
Quick Answer
• What it is: Industrial AI is AI applied in environments where machine uptime, operational risk, and system integration govern the design, so it must read trusted data from systems like MES, SCADA, and ERP, fit existing control and approval workflows, and behave safely and predictably.
• How it differs: Generic AI optimizes for plausible language; industrial AI is judged on reliability, integration, governance, and often latency and safety, where a confident wrong answer is a feature failure on the floor.
• When deployment changes: Sensitive process data, near-real-time latency, and governance or compliance constraints are the signals that push a manufacturer toward private or hybrid deployment.
• Why it matters: Real production results show up only when the AI is bound to a clean data path, an explicit approval step, and a named owner, not when a model is dropped onto the floor.
What Does Industrial Artificial Intelligence Mean?
Industrial AI is AI applied in environments where machine uptime, operational risk, and system integration govern the design. It is not a category of model. It is a category of context. The same large language model that drafts a marketing email becomes industrial AI the moment it has to read trusted data from a manufacturing execution system, fit inside an existing control and approval workflow, and behave safely and predictably near a running line. What makes it industrial is not what the model is. It is what the model is allowed to touch and what happens if it is wrong.
That context flips the priorities. In a consumer tool, a clever answer that is occasionally wrong is acceptable, because a person reads it and moves on. On a plant floor, the cost of being wrong is measured in stopped lines, scrapped output, or a safety event. So industrial AI is designed backward from the consequence: what data can it trust, which decisions can it make on its own, which require a human to approve, and where does it have to live so the data and the decision stay inside the manufacturer's perimeter. The technology is ordinary. The constraints are not.
How Is Industrial AI Different From Generic AI?
The clearest way to see the difference is to put the design priorities side by side. Generic and consumer AI is optimized to produce plausible, fluent language. Industrial AI is optimized to be reliable, integrated, governed, and bounded by the realities of a physical operation. A confident but wrong answer is a charming quirk in a chatbot and a feature failure on the floor. This distinction is becoming the real dividing line as adoption broadens: the Federal Reserve's FEDS note on monitoring AI adoption in the U.S. economy found that roughly 18% of all firms had adopted AI by year-end 2025, while 78% of the labor force already worked at a firm that had, and over 20% planned to adopt in the first half of 2026. Plenty of that adoption is generic office AI. The harder, slower work is the industrial kind described below.
| Dimension | Generic / consumer AI | Industrial AI |
|---|---|---|
| What it optimizes for | Plausible, fluent output | Reliable, predictable, safe behavior |
| Cost of being wrong | A user re-reads and moves on | Stopped line, scrap, or a safety event |
| Data it relies on | Open web and general text | Trusted MES, SCADA, ERP, and historian data |
| Integration | Standalone app or chat window | Wired into legacy control and business systems |
| Decision authority | Acts freely on the user's request | Bounded by approval logic and human oversight |
| Latency tolerance | Seconds are fine | Often near-real-time for control loops |
| Where it runs | Public cloud, anywhere | Often inside the plant perimeter or hybrid |
Here is the false belief worth killing early. Most leaders think industrial AI is just regular AI pointed at a factory. They are wrong. The model may be identical, but the engineering around it is a different discipline, because every column in that table is a constraint a consumer tool never has to satisfy. Treating a plant deployment like a chatbot rollout is the fastest way to fund a pilot that demos well and never earns a place near the line.
See which workflows are actually industrial-grade
A free AI Assessment maps your operation against these constraints and tells you which workflows are worth automating and what architecture they need.
Book Your Free AI Assessment →
Why Does Industrial Context Change the Design Requirements?
The reason the design changes is that the tolerance for failure changes. The NIST AI Risk Management Framework names the characteristics of a trustworthy AI system, and reading them through a plant lens shows exactly why industrial AI cannot be built like a consumer one. NIST holds that a trustworthy system should be valid and reliable, safe, secure and resilient, accountable and transparent, explainable and interpretable, privacy-enhanced, and fair. In a marketing tool, most of those are nice to have. Near a running line, several of them are the difference between a useful system and a hazard.
Valid and reliable stops being a quality metric and becomes a safety requirement: a model that is right most of the time is not good enough when the wrong answer can stop production. Safe and secure and resilient matter because the system sits next to physical equipment and is a target. Accountable, transparent, and explainable matter because an operator has to be able to ask why the system recommended an action before trusting it with a consequential one. And privacy-enhanced ties directly to the deployment question, because proprietary process data often cannot leave the plant. Generic AI can skip most of this. Industrial AI cannot.
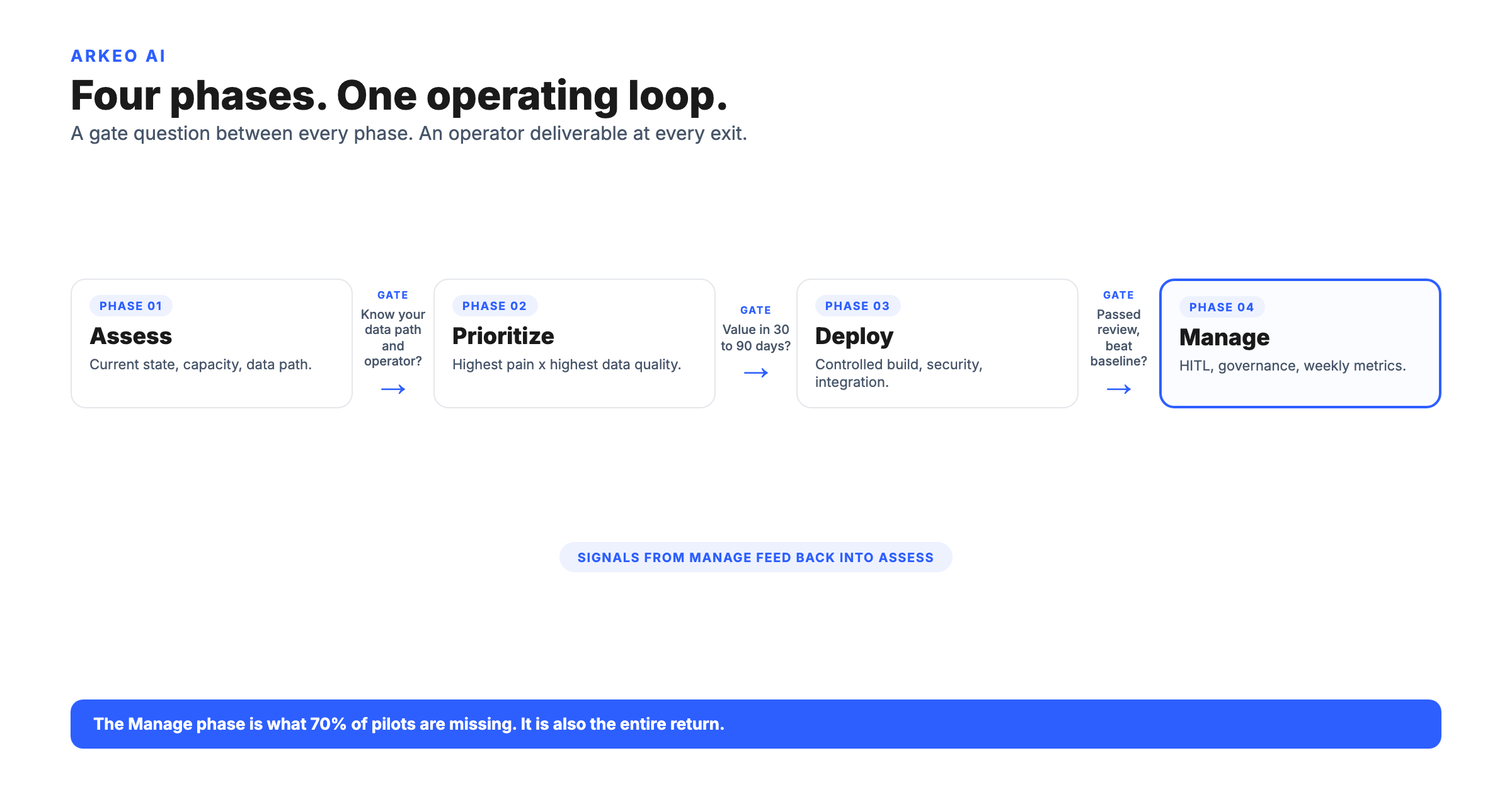
NIST also gives you the operating model in its four core functions: Govern, Map, Measure, and Manage. The blunt truth most vendors leave out of the brochure is that this is not a one-time install. You govern the use, map the context and the risk, measure how the system actually performs in the operation, and then manage it continuously, because a plant model drifts as equipment, materials, and conditions change. An industrial AI system without a Manage function is not a finished system. It is a future incident waiting for the conditions that expose it.
Where Does Industrial AI Show Up?
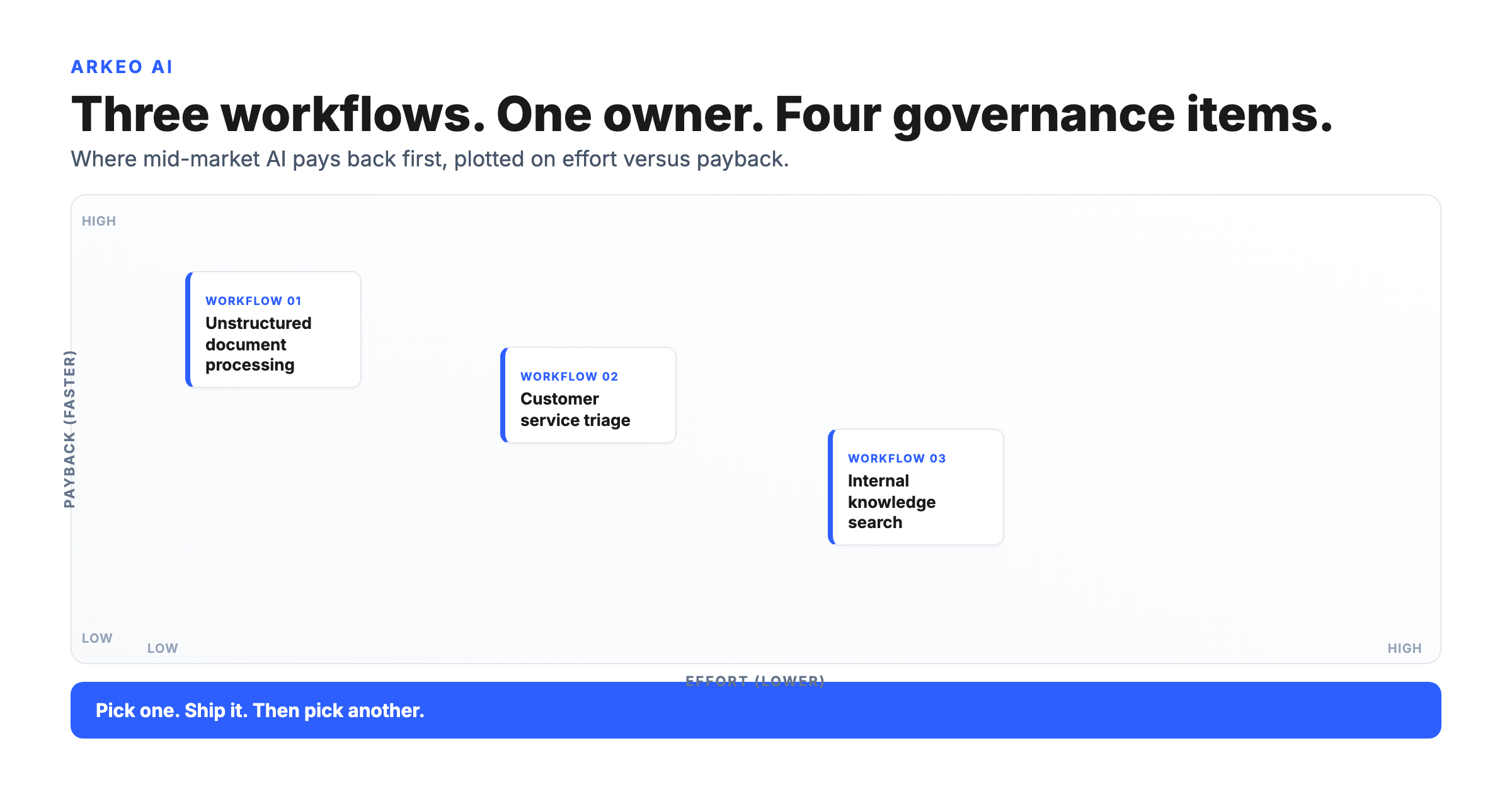
Industrial AI is not one application. It is a set of jobs that share a pattern: each one is bound to a data path, an approval step, and an owner. Five families cover most of what reaches production.
Operations. Agents that read live process data and surface anomalies, recommend setpoint adjustments, or flag conditions a human then confirms. These are the most latency-sensitive and the most tightly governed, because they sit closest to control.
Maintenance. Models that read sensor and equipment history to predict a failure before it stops the line. The value is real, but it depends on instrumented assets and a record of past failures to learn from, and the recommendation almost always routes to a person before a work order is issued.
Quality. Vision and anomaly models that inspect output at line speed, catching defects more consistently than a human at the end of a shift. This is often the cleanest entry point because the data already exists as parts moving down a line.
Planning. Agents that rebalance a schedule against orders, capacity, material, and downtime far faster than a planner with a spreadsheet. The hard part is integration and trust, not the math, because the agent is only as good as the MES and ERP data it reads.
Knowledge and document workflows. Generative agents that draft deviation reports, answer operator questions about work instructions, and reconcile records across systems. This is the least disruptive family because it touches systems of record rather than the line, which is why many plants start here. It is the same category covered in the broader work on AI industrial automation.
What Does Industrial AI Need to Work?
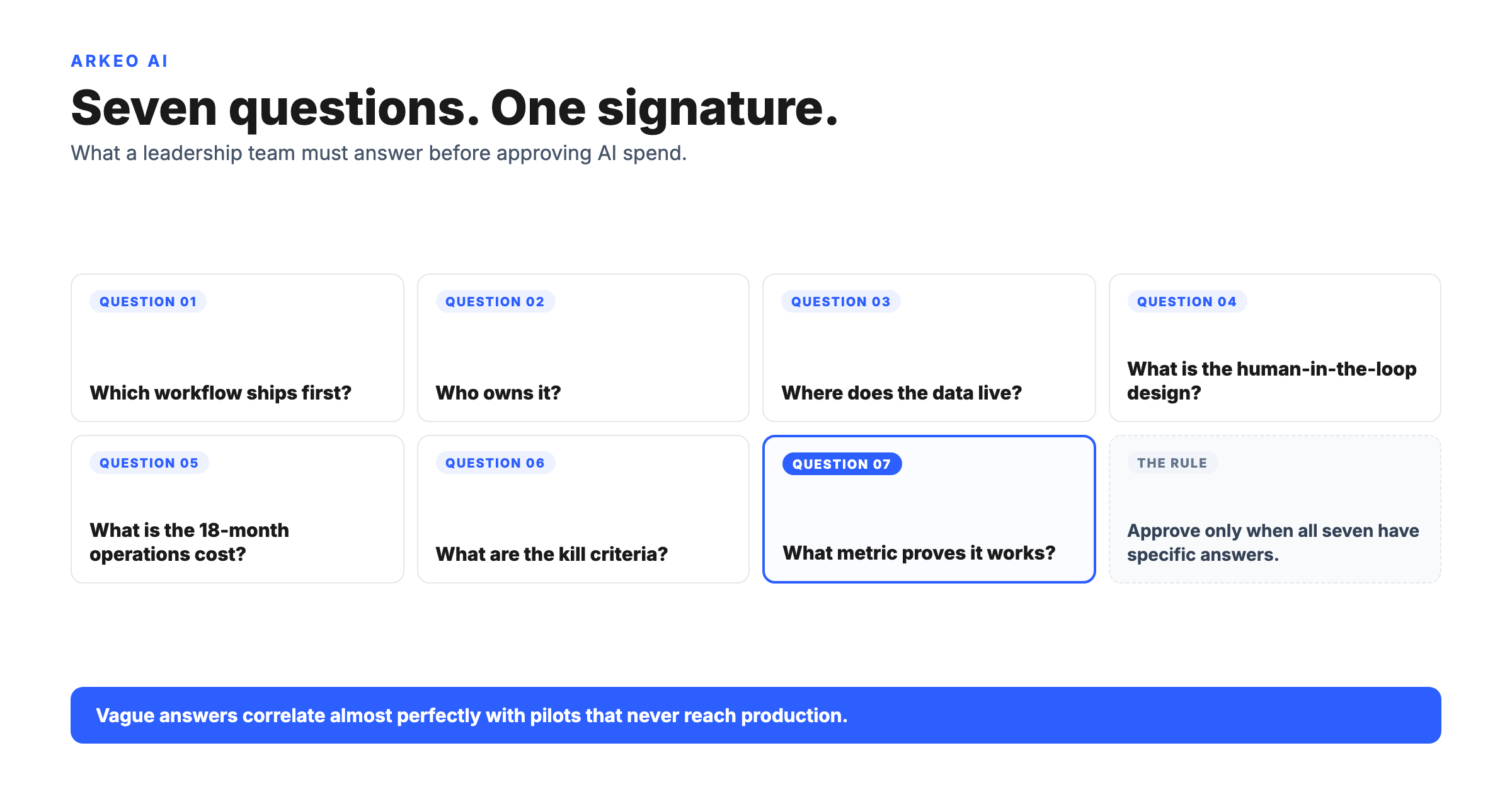
Strip away the use case and every durable industrial AI deployment shares the same four requirements. They are unglamorous, and they are where projects actually succeed or fail. The four move in sequence, which is why the requirements look like a flow rather than a checklist.
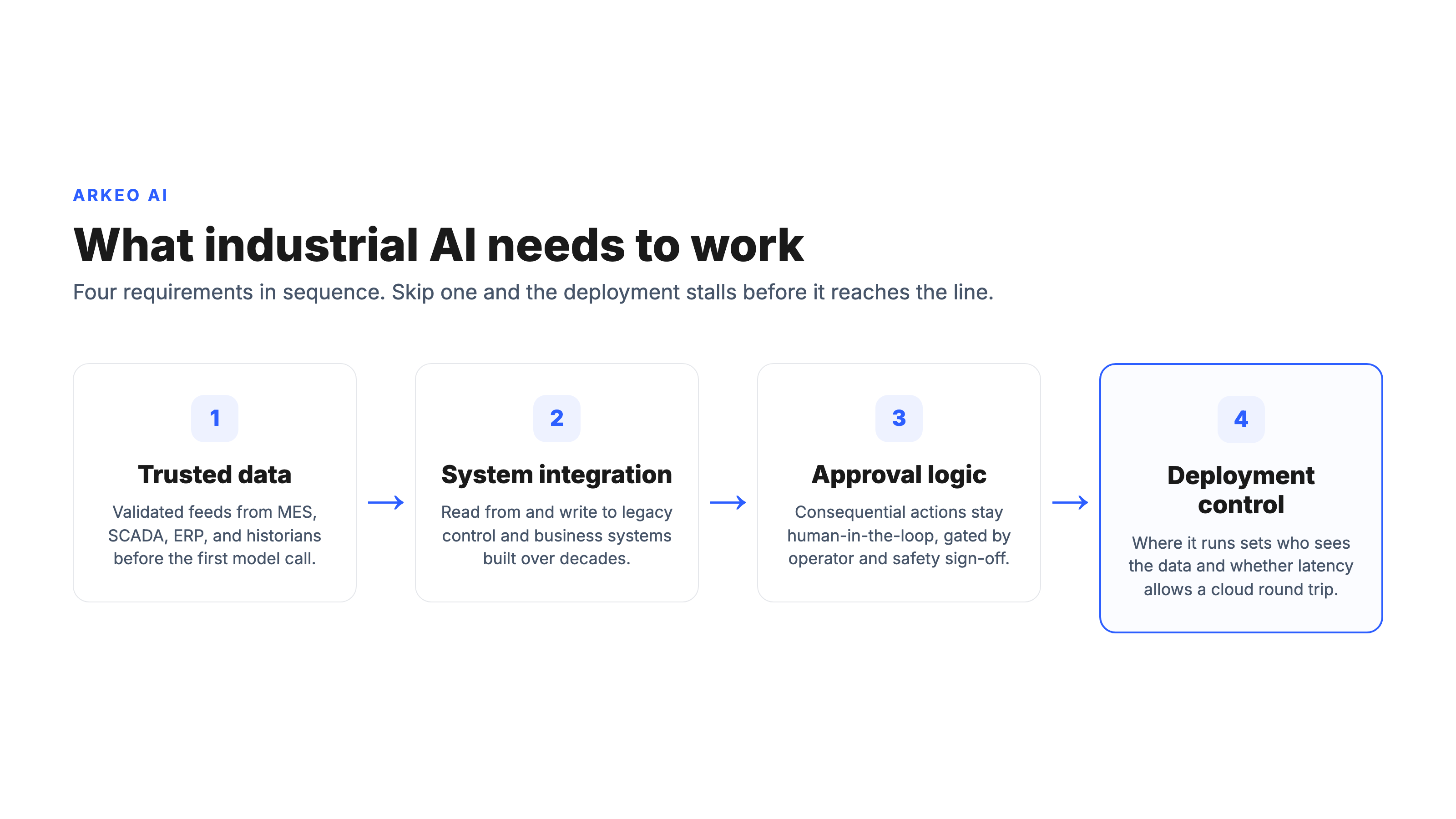
The order is not cosmetic, and it reflects how the work actually lands in Arkeo's deployments. The first weeks go to wiring and validating one MES, SCADA, ERP, or historian feed before the first production-grade model call, because a model pointed at unvalidated data is wrong before any algorithm choice matters. Once the data path is trusted, consequential actions stay human-in-the-loop, gated by operator review and safety sign-off rather than fired automatically. And control-adjacent decisions need near-real-time latency, which is why a cloud round trip can be disqualifying for the workloads that sit closest to the line. The diagram below shows where the AI sits once those requirements are met: between the data sources it reads, the business systems it acts on, and the human approvals that gate its consequential decisions.
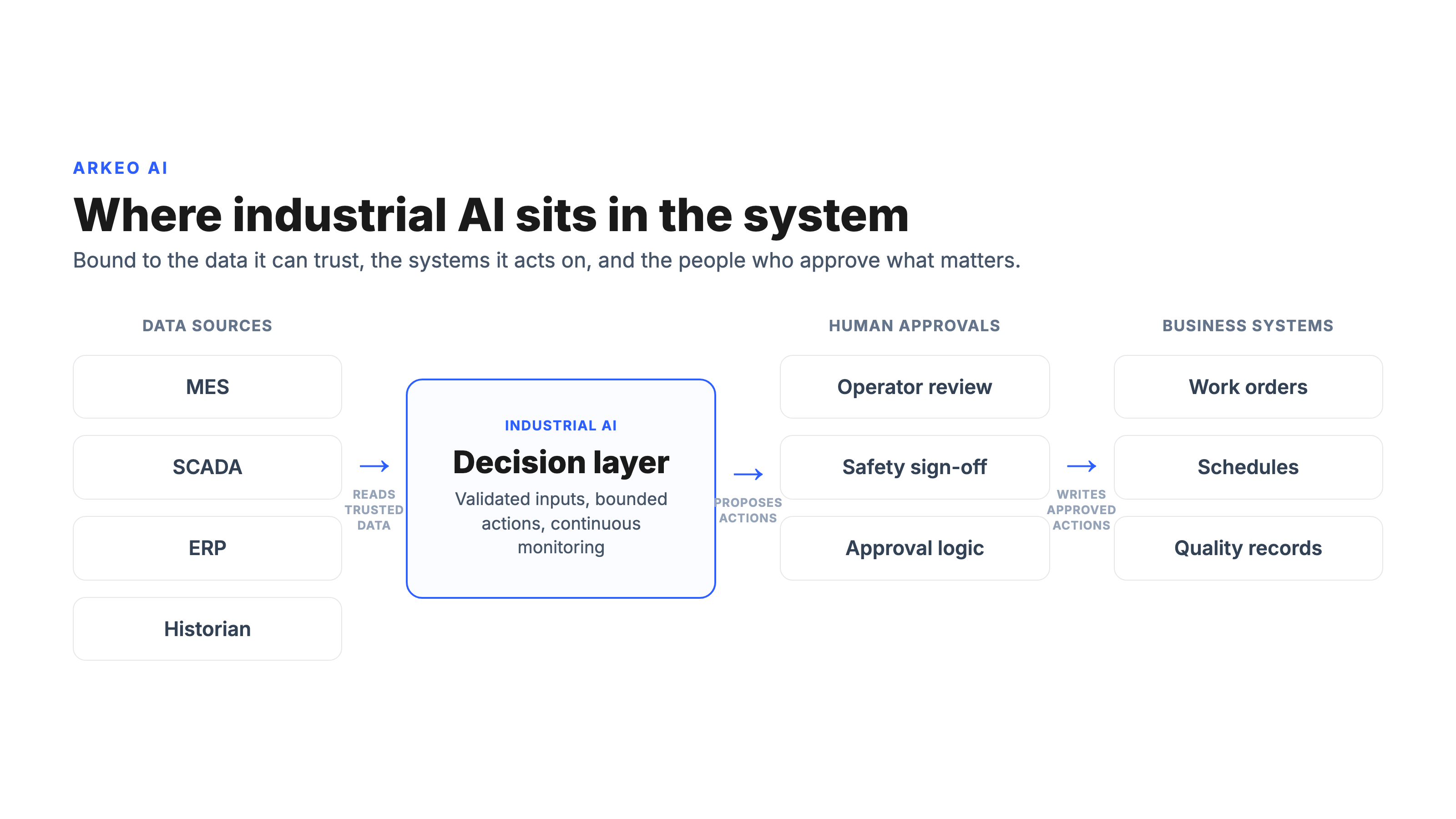
Trusted data. The system has to read validated data from the plant's systems of record, the MES, SCADA, ERP, and historian feeds. A model fed half-maintained ERP fields or a drifting sensor is wrong before any algorithm choice matters. This is the requirement that absorbs the opening stretch of a real deployment, measured in weeks, not days.
System integration. Industrial AI lives inside a stack that was built over decades. It has to read from and write to legacy control and business systems that were never designed for it. Integration, not intelligence, is usually the gating constraint on the plant floor.
Approval logic. Consequential actions need a human in the loop. The system proposes; a qualified person disposes. Defining which decisions the AI can make on its own and which require sign-off is a design choice, not an afterthought, and it is how a plant keeps the NIST accountability characteristic real rather than aspirational.
Deployment control. Where the system runs determines who can see the data and how fast it can respond. For a plant handling sensitive process IP or running near control loops, that question is not a detail. It is the design.
When Do Manufacturers Need Private or Hybrid Deployment?
Most general AI runs in the public cloud, and for plenty of industrial workloads that is fine. But three signals reliably push a manufacturer toward keeping the AI inside its own perimeter, on-premise or in a hybrid arrangement. When one or more of these is present, the deployment model stops being an IT preference and becomes part of the safety and governance design.
Sensitive process data. Proprietary recipes, process parameters, yield data, and quality records are often the most valuable IP a manufacturer owns. If that data cannot leave the plant, the AI that reads it cannot either. This is the most common reason a plant chooses a private deployment, and it is covered in depth in the work on keeping proprietary process data on-premise.
Latency. Workloads near a control loop cannot afford a round trip to a distant data center. When a recommendation has to arrive in near real time, the inference has to run close to the line, which often means on-premise or edge compute rather than a public cloud call.
Governance and compliance. Regulated output, audit requirements, and data-residency rules can make a public-cloud deployment a compliance problem on its own. Keeping the data and the decisions inside the manufacturer's controlled environment is sometimes the only configuration that satisfies the rules.
The practical answer for most plants is not all-or-nothing. A hybrid split, with sensitive and latency-bound workloads on-premise and everything else in the cloud, is a common and defensible architecture. The trade-offs are laid out in the comparison of cloud AI versus on-premise AI. This is a genuine Arkeo capability rather than a talking point: Arkeo deploys on-premise and private AI for exactly these environments, because some industrial workloads have nowhere else to safely run.
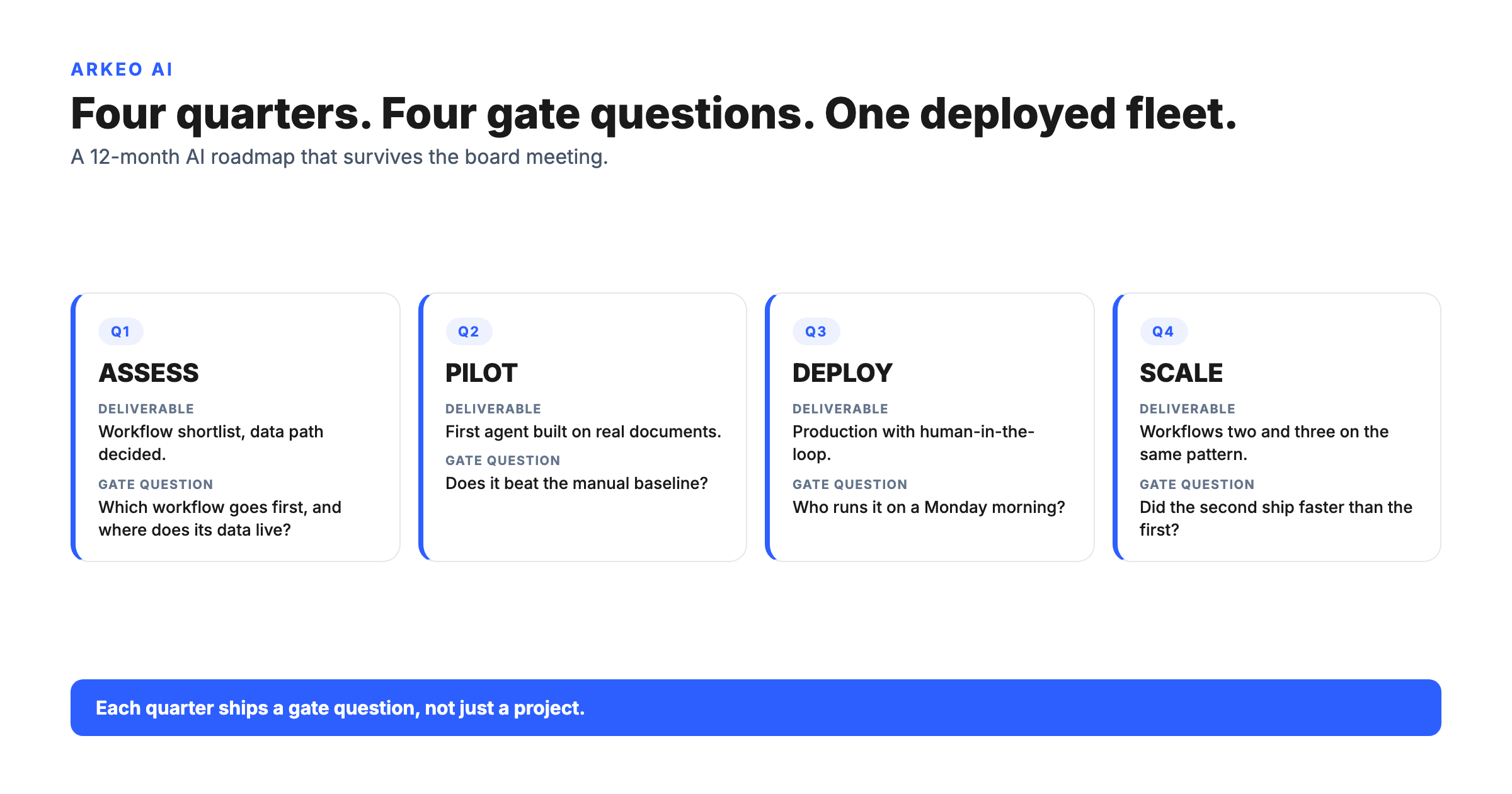
How Do You Evaluate an Industrial AI Opportunity?
You do not evaluate an industrial AI opportunity by starting with the model. You start with the context and the constraints, and the NIST core functions give you a clean set of readiness questions to run before committing a budget. Map the context: what is the bottleneck, and what data already reaches it. Govern the use: who owns the workflow, and which decisions require human approval. Then weigh the selection criteria honestly.
Run a candidate through three filters. First, data readiness, because a high-value use case with no clean data path is a later project, not a first one. Second, safety and approval constraints, because anything that touches worker safety or regulated output raises the bar on human oversight and is held to the NIST safety and accountability characteristics. Third, deployment requirements, because sensitive data or latency may force a private or hybrid build that changes the cost and timeline. A use case that clears all three, with a named owner, is a real opportunity. One that fails any of them is a signal to fix the gap first. The Arkeo Operating System exists precisely because scattered pilots do not survive contact with a real plant while an owned, governed architecture does. We use what we sell.
Map your industrial AI opportunity
A free AI Assessment runs your candidate workflows against data readiness, safety, and deployment constraints, then shapes the architecture each one needs.
Book Your Free AI Assessment →