Category
Generative AI Strategy: From ChatGPT to Custom Agents
Last updated: June 4, 2026
If you run a mid-market business where half the staff are already pasting customer records into the public ChatGPT tab, leadership knows it is happening, and the board now wants a generative AI strategy, this guide is for you. The risk is not theoretical: the IBM Cost of a Data Breach 2025 report found shadow AI usage adds $670,000 to the average breach, and 97 percent of organizations that suffered an AI-application breach lacked proper access controls. In this guide, you'll get the four-stage maturation path (scattered ChatGPT, governed Enterprise, private RAG, custom agents), the gate criteria between each, and where the data sovereignty pivot has to happen.
The IBM Cost of a Data Breach 2025 report places the dollar figure on Stage 1; what most operators miss is that the path out is not one decision, it is four. Before the next slide deck on generative AI gets written, map where you are; a free AI Assessment names the stage you are at today and the gate criteria that will move you to the next one.
Quick Answer
• What it is: A generative AI strategy is the sequenced four-stage maturation from scattered ChatGPT use to custom AI agents acting on workflows.
• The four stages: Scattered ChatGPT, governed ChatGPT or Enterprise tier, private RAG over internal documents, custom agents that act on workflows.
• The pivot: Stage 3 is where data stops leaving the building.
• Why it matters: Skipping a stage is faster than fixing what skipping it produces.
Why are most mid-market companies stuck at Stage 1?
Most companies are stuck at Stage 1 because the default starting state of generative AI inside a business is scattered, unmanaged use of public ChatGPT, and graduating out of that state requires four sequential decisions almost nobody makes up front. The pilot, the prompt library, and the policy memo are all symptoms of trying to skip those decisions.
The Stanford HAI 2025 AI Index reports 78 percent of organizations used AI in 2024, up from 55 percent the year before. Adoption is the baseline now; sequencing is the differentiator. On the deployment side, the Deloitte State of Generative AI Wave 4 study of 2,773 C-suite respondents found more than two-thirds expect 30 percent or fewer of their generative AI experiments to scale within three to six months. BCG's Where's the Value in AI? report from October 2024 reached the same conclusion from a different angle: 74 percent of companies are struggling to capture value from AI. The pattern is not that the models are weak. The pattern is that the maturation path is treated as a binary jump, and the gate between scattered ChatGPT and a deployed custom agent is four stages, not one.
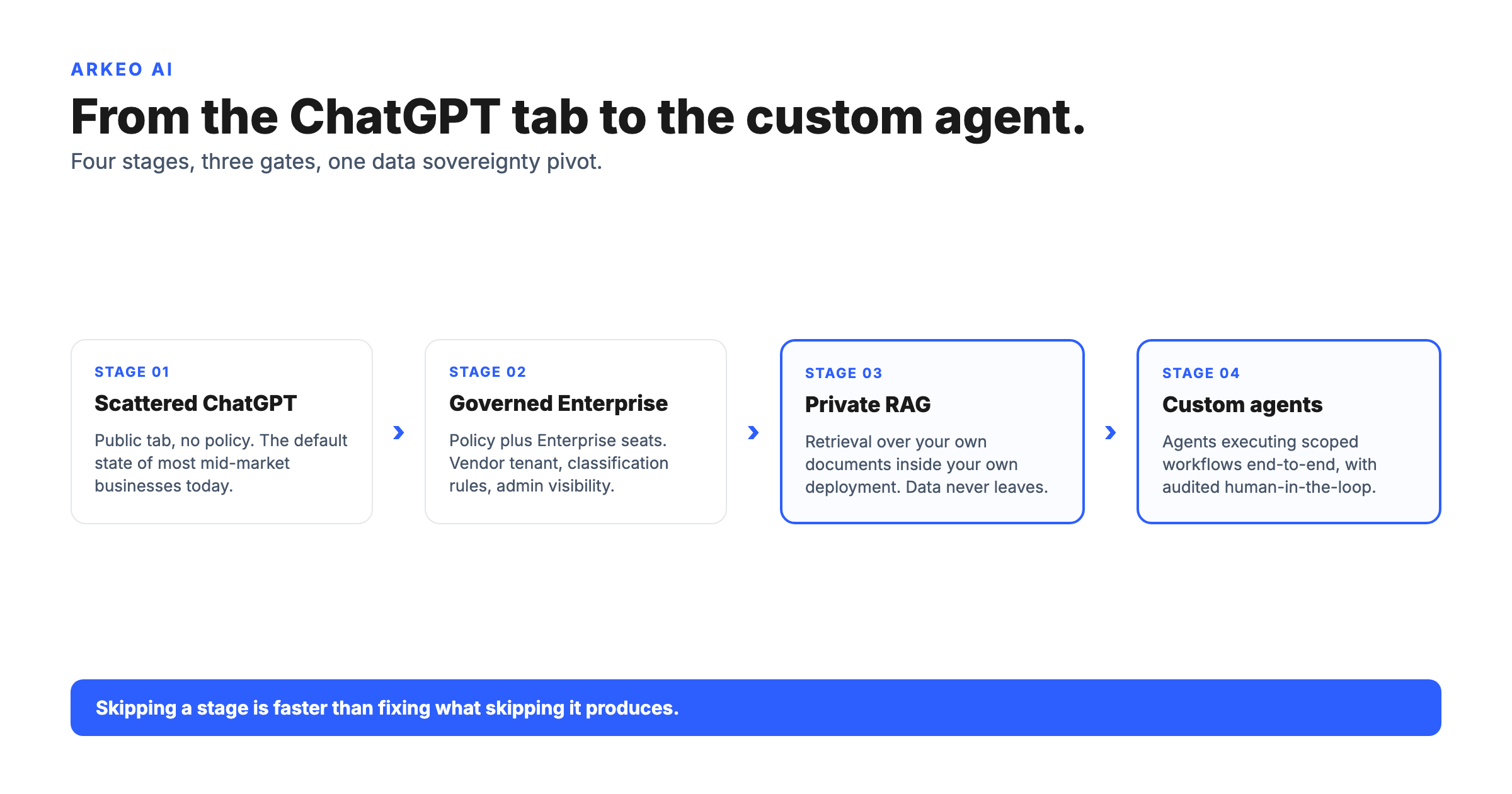
The simpler way to think about this: a generative AI strategy is the answer to four sequential questions about where you are and what has to be true to advance. The maturation path that follows is the spine of any credible enterprise AI strategy.
What are the four stages of generative AI maturation?
The four stages compress the entire generative AI conversation into a path that operators can map themselves onto. Each stage has a default texture, a gate to the next stage, and a data risk worth naming.
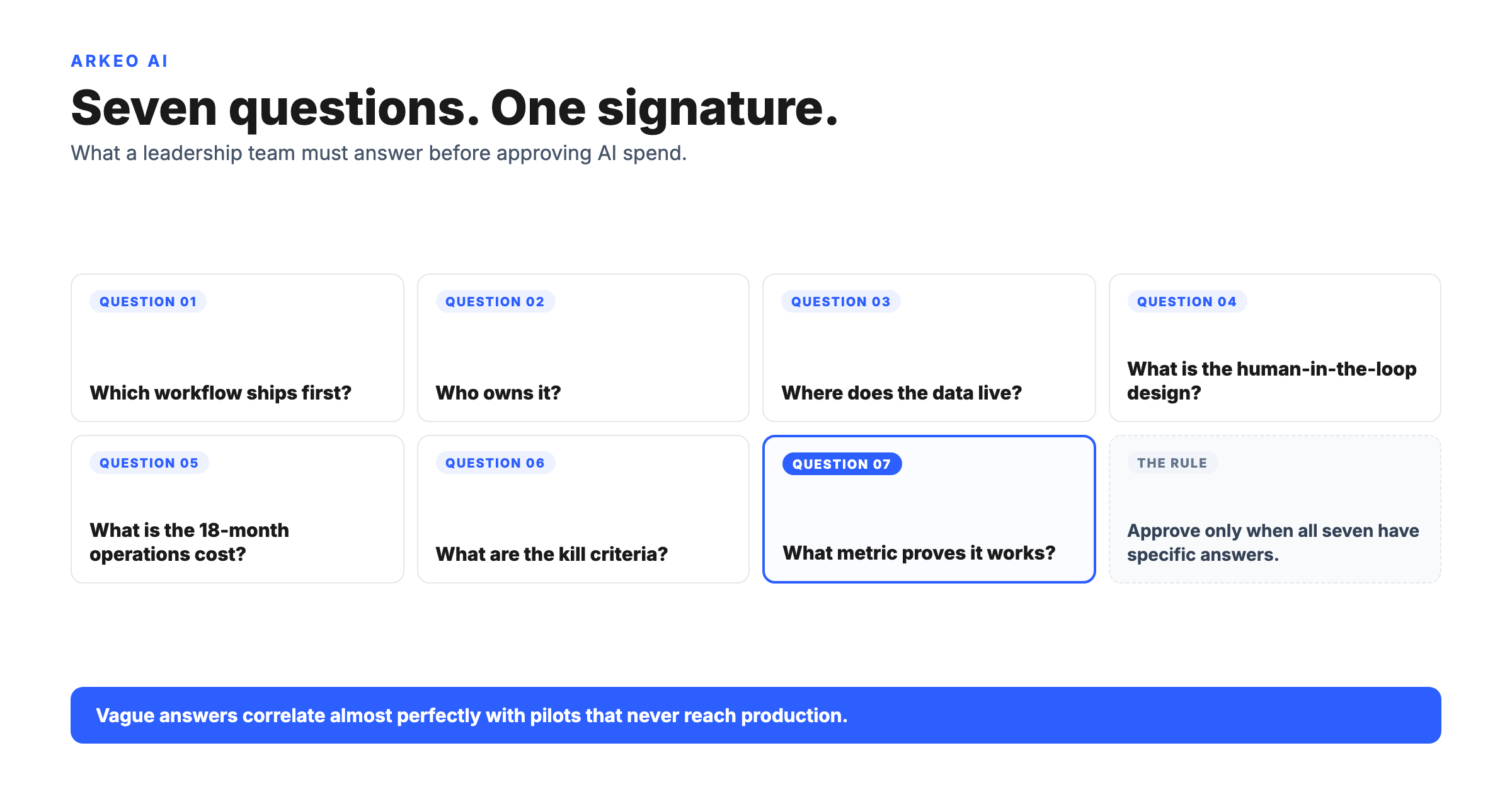
THE MATURATION PATH
Four stages from ChatGPT to custom agents
Each stage has a gate question. If you cannot answer it, the stage is not actually complete.
STAGE 01
Scattered ChatGPT
The default state. Staff pasting customer records, contracts, and source code into the public ChatGPT tab, no policy, no classification rules, no audit trail.
Gate to advance: Is there a written acceptable-use policy and an enterprise account that staff actually use?
Data risk: Shadow AI adds $670K to the average breach cost (IBM 2025).
STAGE 02
Governed ChatGPT or Enterprise tier
Enterprise seats deployed, classification rules in place, training delivered. Staff know what they can paste and what they cannot.
Gate to advance: Is there a workflow where the answer requires your private documents, not the open web?
Data risk: Vendor tenant still holds the conversation; admin visibility, not sovereignty.
STAGE 03
Private RAG over internal docs
Retrieval over your own documents inside your own deployment. Data never leaves the building. Citations come back tied to the source file.
Gate to advance: Is there a workflow where the agent should act on the answer, not just return it?
Data risk: Lower; retrieval is scoped, logged, and inside the firewall.
STAGE 04
Custom agents acting on workflows
Agents executing scoped workflows end-to-end: drafting, routing, updating systems of record, with human-in-the-loop review at the points that matter.
Gate to advance: Is there a second workflow that can reuse the same private deployment and the same operating model?
Data risk: Action paths require audited HITL gates; risk shifts from leakage to action quality.
Skipping a stage is faster than fixing what skipping it produces.
What does Stage 1 actually look like inside a real business?
Picture a 300-person professional services firm. Roughly half the staff use ChatGPT weekly. The CFO uses it to summarize board materials. A junior analyst uses it to clean up client letters. Two account managers use it to draft proposals from prior winning ones, which means the prior proposals, the client names, and the pricing have all been pasted into a public model. There is no acceptable-use policy. The legal team has flagged the risk twice in steering committee and been told the topic will be addressed next quarter. That is Stage 1, and it is the operating state of the majority of mid-market businesses today.
Beyond the breach numbers above, the same IBM 2025 report found 13 percent of organizations reported a breach of AI models or applications, evidence that the Stage 1 risk now lands in incident data, not just policy memos. The deeper governance pattern is unpacked in the dedicated post on shadow AI governance, which is the right rabbit hole when the Stage 1 to Stage 2 gate becomes the priority.
What changes at Stage 2, and is it enough?
Stage 2 is the policy stage. The business buys ChatGPT Enterprise seats, ChatGPT Enterprise lists at roughly $25 per user per month as a market reference from OpenAI, drafts an acceptable-use policy, classifies the document types staff can and cannot paste, and runs a training session that sticks because the alternative is no AI access. The risk surface narrows. The vendor logs the conversations under enterprise terms, the admin can see usage, and the obvious leakage modes close.
What Stage 2 does not change is where the answers come from. ChatGPT Enterprise still answers from the open web and the model's training data. The proposals your account managers draft are still patterned on the public corpus, not on the last three years of your won and lost proposals. The contracts your legal team reviews are still summarized against generic templates, not against the master service agreement you actually use. Stage 2 makes the existing use safe. It does not make the existing use yours. The gate to Stage 3 is the moment one of those workflows would clearly be better if the model had access to your own documents.
Find the workflow that should move past Stage 2One 60-minute free AI Assessment maps your current stage, names the gate criteria to advance, and identifies the one workflow worth taking to private RAG first.
Book Your Free AI Assessment →
What is the data sovereignty pivot at Stage 3?
Stage 3 is where the strategy stops being a policy question and becomes an architecture question. The model retrieves from your documents inside your deployment. The conversation, the source files, the embeddings, and the logs all stay inside the firewall. The answer comes back with citations to the file it came from, so the user can audit it.
Picture a regulated services company at Stage 2 with a workflow that summarizes claims using ChatGPT Enterprise plus copy-paste. The summaries are good. The auditor flags the workflow because the claims data, even under enterprise terms, is being processed by a model the company does not control on infrastructure the company does not own. At Stage 3, the same workflow runs inside a private deployment over the company's own claims archive. The summaries get more accurate because the retrieval is over the company's own playbook, not the open web, and the auditor question goes away because the data never leaves. The deeper architecture pattern for mid-market businesses making this pivot is unpacked in private AI for mid-market businesses.
WHERE THE DATA LIVES
Data sovereignty across the four stages
The sovereignty answer is the line that separates Stage 2 from Stage 3.
STAGE 01
Scattered ChatGPT
Data lives: Public model provider.
Who sees it: Whoever the vendor lets see logs.
STAGE 02
Governed ChatGPT
Data lives: Vendor tenant, with policy.
Who sees it: Vendor plus admin.
STAGE 03
Private RAG
Data lives: Your private deployment.
Who sees it: Your team plus explicit access.
STAGE 04
Custom agents
Data lives: Your private deployment plus workflow systems.
Who sees it: Your team plus audited HITL.
The Stage 3 pivot is where "data never leaves the building" becomes real.
In Arkeo's build experience a scoped private RAG deployment over a single workflow runs about $15,000 to $40,000 and reaches production in 6 to 10 weeks, or 8 to 12 weeks for enterprise-grade scope; the first quick win typically lands inside 30 to 90 days. The reason the same numbers come up over and over is that the build sequence is repeatable: scope one workflow, ingest the documents that workflow depends on, ship the retrieval, layer the policy, and only then move to the next workflow. The narrower point about who owns and orchestrates that build sequence is covered in the AI strategy framework.
What does Stage 4 add, and why does sequencing matter?
Stage 4 is where the model stops returning answers and starts taking actions. The agent reads a claim, drafts the summary, classifies the claim against the playbook, opens the case in the system of record, and routes it to the human reviewer with the citations attached. The PwC AI Agent Survey of 300 senior US executives found 79 percent of US businesses already adopting AI agents and 66 percent of adopters reporting measurable productivity gains. The bar at Stage 4 is not whether agents work; the bar is whether the operating model is mature enough to run them safely.
That maturity is the reason sequencing matters. A business that jumps from Stage 1 straight to Stage 4 builds an agent on top of unclassified data, with no policy, no operating runbook, and no internal practice in reading model output critically. The agent ships, the first incident lands, the agent gets pulled, and the business goes all the way back to Stage 1 with a worse reputation than it started with. A business that walks the stages reuses every prior decision: the policy from Stage 2 becomes the guardrails for Stage 3, the private deployment from Stage 3 becomes the runtime for Stage 4, and the operating model from Stage 3 becomes the rhythm for Stage 4. Arkeo deploys this kind of private AI workforce on your infrastructure under the Assess, Deploy, Manage model. "We use what we sell" applies here: the same private agents Arkeo deploys for clients run Arkeo itself.
How do you know which stage you are actually at?
The honest answer is rarely the one on the strategy slide. Three diagnostic questions usually settle it. First, can you point to a written acceptable-use policy and an enterprise account that staff actually use? If no, you are at Stage 1, regardless of what was approved last quarter. Second, is there a workflow whose quality clearly depends on your own documents, and is that workflow currently being handled by a public or vendor-hosted model? If yes, you have a Stage 2-to-Stage 3 pivot waiting. Third, is there a workflow where the agent should be taking the next action, not just producing the answer, and is the operating model ready for it? If yes, Stage 4 is on the table. If any of those answers are uncertain, the assessment is the cheap way to make them concrete.
Name your stage and your next gateThe free AI Assessment maps your generative AI strategy onto the four-stage path, names the stage you are actually at, and identifies the next gate to advance.
Book Your Free AI Assessment →