Category
AI Predictive Maintenance in Manufacturing
Last updated: May 2026
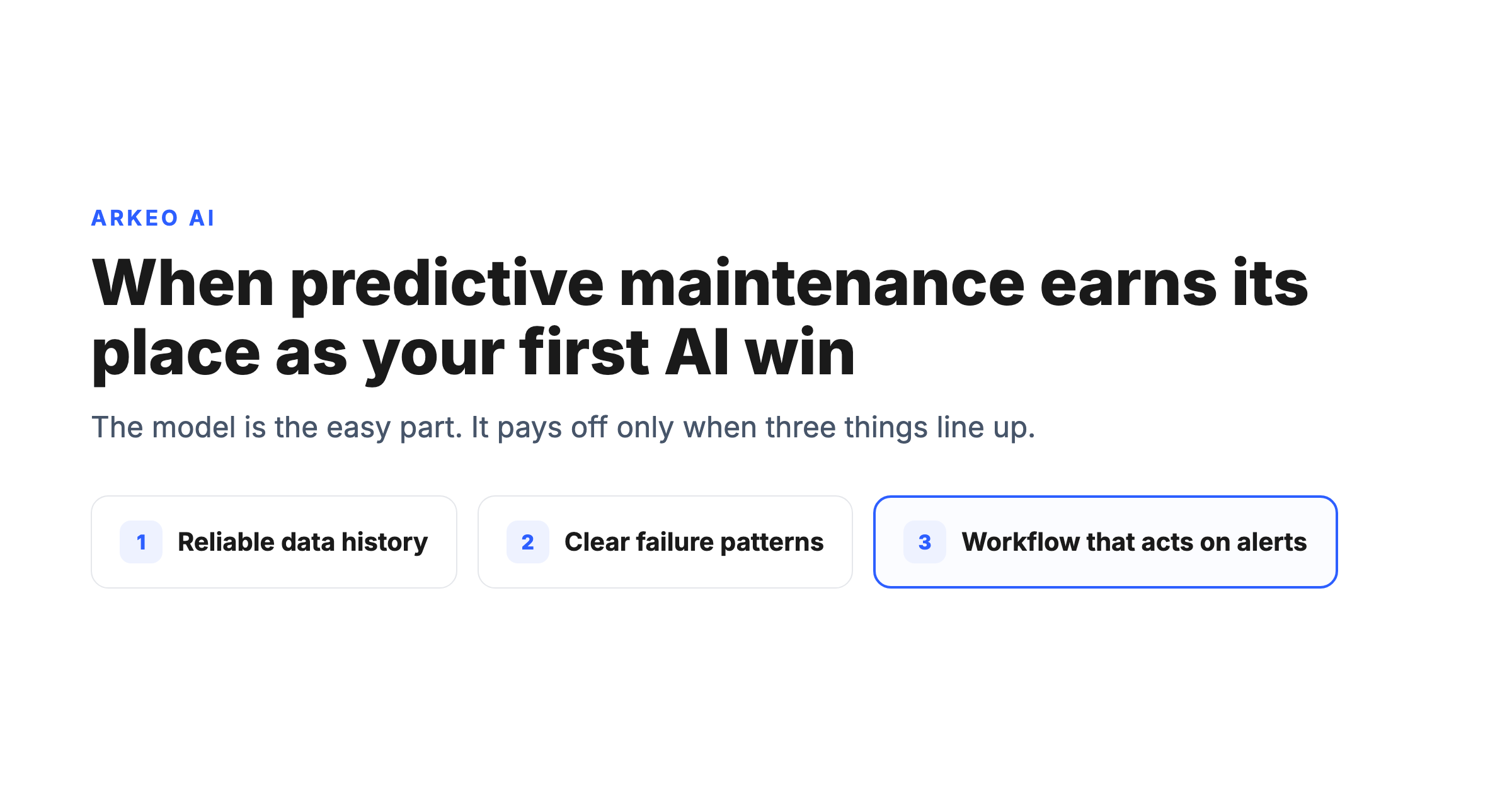
You have heard it a hundred times: predictive maintenance is the textbook first AI project for a plant. Catch the bearing before it seizes, schedule the repair on your terms, stop bleeding money on unplanned downtime. The pitch is clean. The reality is that predictive maintenance is one of the most demanding AI use cases to get right, and for a lot of plants it is not the easiest first win. It needs reliable data history, clear repeating failure patterns, and a maintenance team that actually acts on the alerts. Miss any of those three and you get a model producing warnings nobody schedules against. That is the honest pattern across three years of deploying AI agents inside operating businesses: the model is rarely the hard part. The workflow after the prediction is.
Arkeo AI was founded in 2023 on 25 years of operating experience and three years deploying agents inside real production environments, and the same lesson keeps surfacing. The teams that win with predictive maintenance are not the ones with the fanciest model. They are the ones who already had the data discipline and work-order follow-through to use it. Before you commit a budget, it is worth pressure-testing whether maintenance is genuinely your best starting point or whether a simpler use case should go first. That is exactly the comparison the free AI Assessment is built to run, and it is the same question this guide on AI in manufacturing keeps coming back to.
Quick Answer
• What it is: AI that reads sensor and maintenance-history data to predict likely equipment failure so repairs are scheduled before a breakdown.
• When it works: reliable data history, clear repeating failure patterns, and a maintenance workflow that triages, approves, schedules, and closes the loop.
• Cost driver: not the model. The sensors, the data plumbing, and the ongoing monitoring program plus the people who act on alerts.
• Why it matters: the U.S. Department of Energy estimates a predictive program saves 8% to 12% over preventive maintenance, and far more where a plant runs heavily reactive.
What Does AI Predictive Maintenance Actually Mean?
AI predictive maintenance uses sensor and history data to predict likely equipment failure so maintenance is scheduled before a breakdown, but it only works when the plant has reliable data history, clear failure patterns, and the workflow discipline to act on the alerts. Strip away the marketing and that is the whole concept. A model watches signals coming off an asset (vibration, temperature, current draw, pressure, cycle counts) and learns the difference between normal operation and the slow drift that precedes a failure. When the drift starts, it raises an alert with enough lead time for a planned repair instead of a 2 a.m. emergency.
The upside is documented. According to the U.S. Department of Energy's Federal Energy Management Program (FEMP) O&M Best Practices Guide, a predictive-maintenance program saves an estimated 8% to 12% over a preventive-maintenance program, and depending on how heavily a facility relies on reactive maintenance, the savings opportunity can exceed 30% to 40%. For context, the same DOE guide notes that moving from purely reactive to preventive maintenance saves 12% to 18% on average. The throughline matters more than any single number: the size of the payoff depends on where you start and on whether you can act on what the model tells you.
How Is It Different From Calendar-Based or Threshold Maintenance?
Most plants today run one of two simpler approaches. Calendar-based (preventive) maintenance services equipment on a fixed interval, every 500 hours or every quarter, whether the asset needs it or not. Threshold-based maintenance trips an alarm when a single reading crosses a hard limit. Both are useful and both are blunt: calendar work replaces healthy parts and still misses early failures between intervals, and threshold alarms fire only once the problem is already advanced.
Predictive maintenance sits a layer above both. Instead of one interval or one limit, it learns the combined pattern across many signals and flags the failure that is forming, not the one that has already arrived. That is the upgrade you are paying for, and it is why the data bar is higher: a fixed interval needs only a calendar, but a model needs history.
Here is the false belief worth retiring early. Most operations leaders assume the model is the project. They are wrong. The model is the cheapest, fastest part to stand up. The expensive, make-or-break parts are the data that feeds it and the workflow that responds to it. Treat predictive maintenance as a data-and-workflow program that happens to use a model, and the odds shift in your favor.
When Does AI Predictive Maintenance Actually Work?
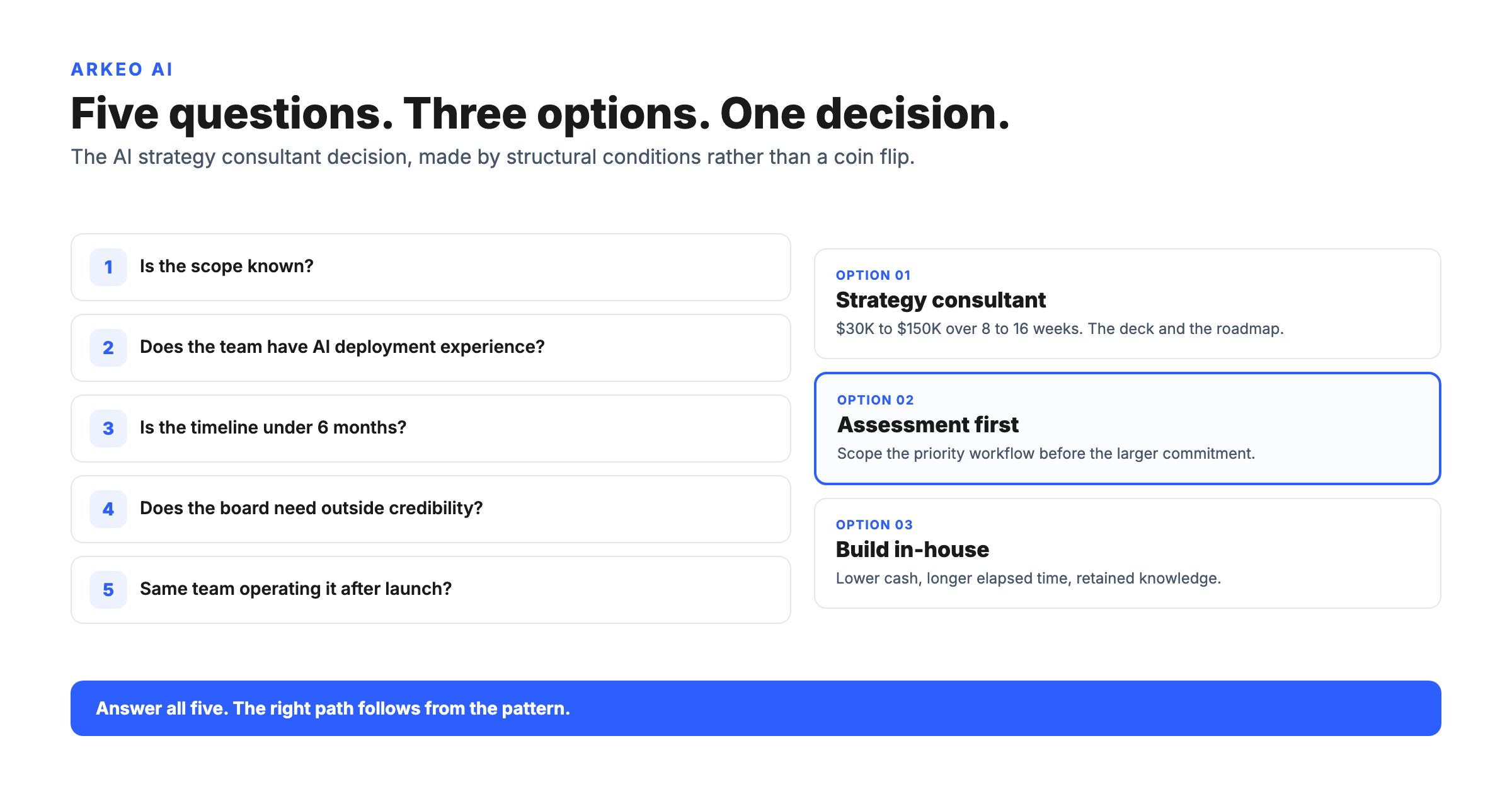
Three conditions have to be true together. Not two of three. All three.
You have reliable data history with labeled outcomes. A model learns failure by example. It needs a meaningful run of historical sensor data plus a record of what actually broke and when, ideally captured in a maintenance system. If your historian has six clean months and your failure records live in a technician's memory, the model has nothing to learn the failure signature from. Enough history with labeled outcomes is the entry ticket.
You have clear, repeating failure patterns. Predictive maintenance shines on assets that fail in recognizable ways: bearings, motors, pumps, gearboxes, compressors. If an asset class fails rarely, randomly, or for reasons that never repeat, there is no pattern to detect. Pick the assets that fail the same way more than once.
Someone acts on the alert. This is the one that quietly kills projects. A prediction is worthless unless a human triages it, approves a work order, schedules the repair into a production window, hands it to a technician, and closes the loop in the maintenance system. If your work-order follow-through is weak today, an AI layer does not fix it. It just generates alerts that pile up unactioned, the textbook way a promising pilot turns into a science project.
Not sure predictive maintenance is your right first move?
The free AI Assessment maps your data history, failure patterns, and maintenance workflow against the use cases most likely to pay off first, so you commit budget to the win you are ready for.
Book Your Free AI Assessment →
When Does It Turn Into a Science Project?
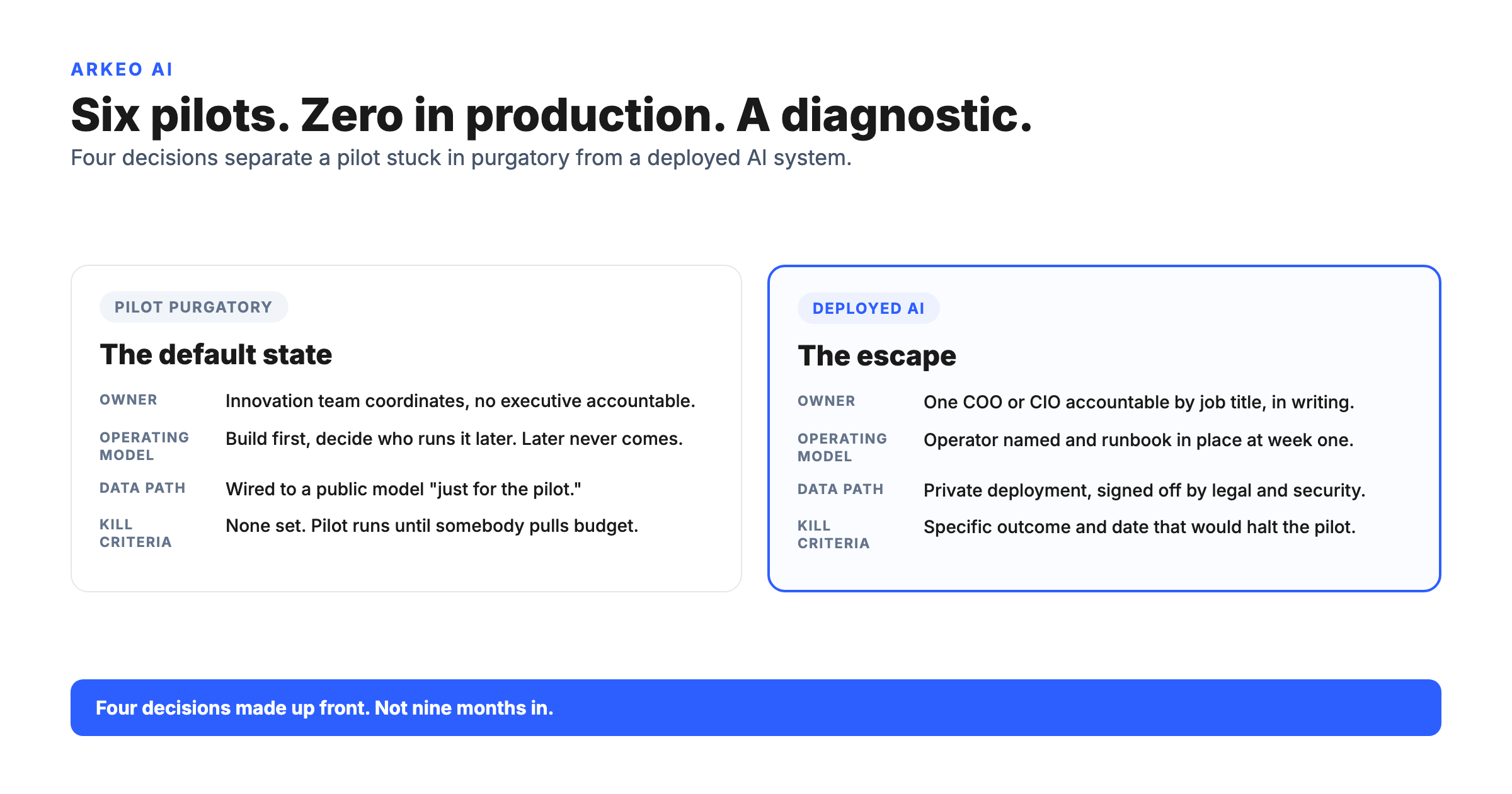
The blunt truth a vendor will not put in a brochure: most failed predictive-maintenance pilots do not fail because the model was bad. They fail because the plant was not ready to use it. Three patterns show up again and again.
Sparse or messy data is the first. No usable history, no labeled failures, sensors that drift or drop out. The model trains on noise and produces predictions nobody can trust. The second is a weak maintenance workflow. The alerts are accurate, but there is no defined owner to triage them and no disciplined path from alert to scheduled work, so the warnings get ignored until the asset fails anyway. The third is no close-the-loop process. Repairs happen but never get recorded against the prediction, so the model never learns whether it was right, and accuracy stalls or drifts. The NIST AI Risk Management Framework frames this as the difference between standing a system up and actually managing it over time. Mapping and measuring a model is the easy half; managing it in production (drift, human review, the response workflow) is where value is won or lost.
If any of those three describe your plant today, predictive maintenance is not your easiest first AI win. It can still be the right destination, but you may get faster, cheaper value from a use case that does not depend on years of clean failure history. That is not a reason to give up on it. It is a reason to sequence it correctly.
How Should You Evaluate the Use Case Before You Commit?
You do not need fabricated ROI promises to make this call. You need three honest checks, in order.
The business case. Put a number on what an unplanned stop on the candidate asset actually costs per hour: lost throughput, scrap, idle labor, expedited parts, missed shipments. Then weigh that against the all-in cost of the program, which is the sensors plus the model plus the ongoing monitoring and the people who act on alerts. If a stop on that asset is cheap, or if it almost never stops, the math does not justify the program no matter how good the model is. The DOE savings ranges above tell you the upside is real and largest where you currently run heavily reactive. They do not tell you it is real on a specific machine. The hourly cost of a stop does.
The data check. Before any modeling, confirm two things. How deep is the usable sensor and maintenance history on this asset class, and how well are past failures labeled (what failed, when, and why). If history is thin or labels are missing, that is your real first project: instrument the asset and start capturing clean records. The model can wait.
The pilot scope. Start narrow. One critical asset class, not the whole plant. Run the model in shadow mode first, where it produces predictions alongside your existing routine so you can measure whether it would have caught real failures before you trust it to drive work orders. A tight pilot that proves the workflow is worth more than a plant-wide rollout that proves nobody reads the alerts.
This is the same disciplined sequencing the AI Assessment applies to every use case, and it is deliberately conservative. The Deloitte 2025 Smart Manufacturing and Operations Survey found that while 29% of manufacturers were using AI at facility or network scale, another 23% were still only piloting it. Most plants are mid-journey, which means a use case only pays when it actually reaches production, not when it stays a pilot.
What Does the Workflow After the Prediction Look Like?
This is the part the model-first pitch skips, and it is the part that decides whether predictive maintenance earns its keep. A prediction is the start of a workflow, not the end of one. Six steps have to connect cleanly.
A sensor signal drifts and the model raises a prediction. A human triages it: is this real, how urgent, which asset, and is it worth interrupting production for. Someone with authority approves a work order, because not every alert warrants a stop and a person owns that judgment. The repair is then scheduled into a production window so it does not blow up the line, and the job is handed to a maintenance technician with the right parts staged in advance. And then, critically, the loop closes: the outcome is recorded in the CMMS against the prediction, so the model learns whether it was right and your accuracy improves over time.
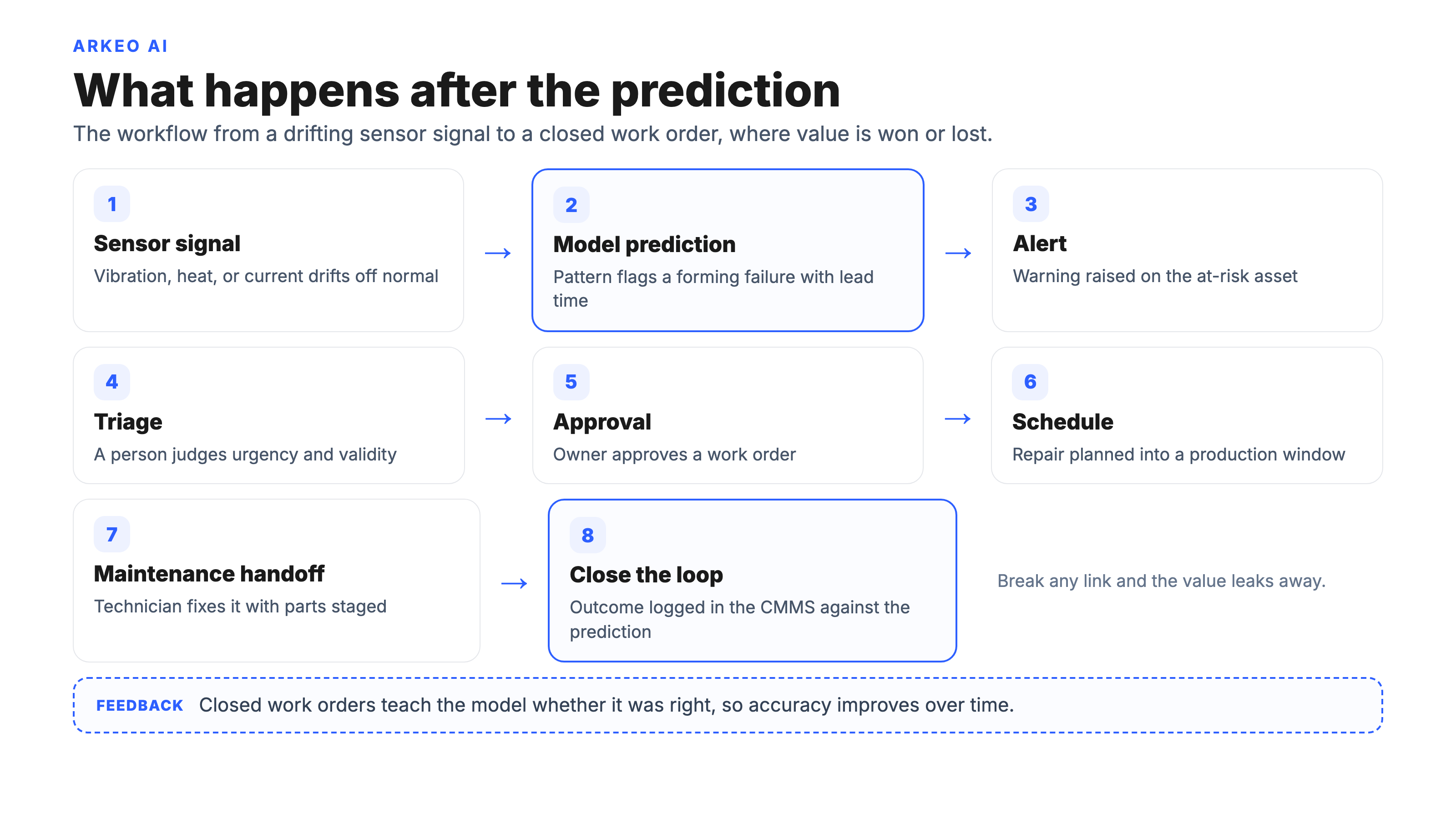
Break any link in that chain and the whole thing leaks value. A great prediction with no triage owner is noise. An approved repair that never gets scheduled is a breakdown waiting to happen. A closed repair that never gets logged is a lesson the model never learns. This is why a mature CMMS and a disciplined maintenance team matter more than the algorithm. The technology is genuinely good now. AI agents still break, drift, and surface false alarms, so the human triage and approval steps are not optional overhead. They are the reason the system stays trustworthy.
Where Does Predictive Maintenance Fit in a Broader AI Roadmap?
Predictive maintenance is one of several manufacturing AI starting points, and it is not automatically the first. The right first use case is the one where your data is already good enough and the workflow is already disciplined enough to act on the output. For some plants that is maintenance. For many, it is something simpler.
If your failure history is thin but your visual defect data is rich, AI for manufacturing quality control often delivers a faster, cleaner first win, because a camera generates labeled examples quickly and the act-on-it workflow (reject the part) is immediate. If your pain is less about machines breaking and more about juggling orders, changeovers, and capacity, AI in production planning can return value without years of sensor history. And if you simply want to understand the landscape of what plants are deploying, the rundown of AI in manufacturing examples is a useful map. The decision table below makes the good-fit versus bad-fit call concrete.
| Decision factor | Good first AI use case | Better to start elsewhere |
|---|---|---|
| Data history | Years of sensor and maintenance records with labeled failure outcomes | Sparse, short, or unlabeled history; failures live in memory or paper logs |
| Failure patterns | Assets that fail in clear, repeating ways (bearings, motors, pumps) | Rare, random, or one-off failures with no detectable signature |
| Maintenance workflow | A CMMS and a team that triages, approves, schedules, and closes work orders | No clear alert owner; weak follow-through; repairs not logged back |
| Cost of a stop | An unplanned stop costs more per hour than the sensor, model, and monitoring program | Downtime on the asset is cheap or so rare the program never pays back |
| Likely better first move | Predictive maintenance is a strong first project | Quality-control vision or production planning may pay off sooner |
Arkeo's approach is deliberately operator-first, and it reflects how this company runs its own business: it deploys the agents it sells, often on-premise and inside the firewall, so the data discipline behind these decisions is lived, not theoretical. The wider context backs the urgency. Federal Reserve research published in April 2026 found that around 18% of U.S. firms had adopted AI by the end of 2025, with over 20% more planning to adopt in the first half of 2026. Adoption is accelerating, which makes it more important, not less, to start with the use case you are actually ready to win.
Start with the use case you can win first
The free AI Assessment compares predictive maintenance against quality, planning, and admin workflows using your real data and workflow maturity, so your first project ships and pays back.
Book Your Free AI Assessment →