Category
Private AI Agents: When To Keep Data Inside
Last updated: May 2026
You already know AI agents can clear backlog, draft documents, and reconcile records faster than any new hire. The question that stops most operators is quieter and harder: where does the data go when an agent does that work? Arkeo was founded in 2023 by people with 25 years running real businesses, and three years deploying agents in real operations, including its own, on-premise and private AI on your stack with your data. We use what we sell: Arkeo runs its own client and operational records, including client contract data, on agents hosted inside its own boundary rather than routing them through a public service, and that private stack is what becomes the Arkeo Operating System (AOS) for a client. The lesson from that work is blunt. The hard part of an AI agent is rarely the model. It is the data path, and whether sensitive records have to leave the building for the agent to function.
Quick Answer
• What they are: private ai agents run inside infrastructure you control (on-premise or a private or hybrid cloud) so prompts, data, and actions stay within your boundary.
• When they matter: when you handle sensitive or regulated data, need strict permissions and audit, or hit integration constraints a public service cannot meet.
• Timeline: a private or on-premise workflow agent moves through discovery, integration, and hardening before going live; cloud options start faster but send data outside your boundary.
• Why it matters: deployment choice is a data-governance decision, not just an infrastructure one. Book a free AI Assessment to decide which model fits your environment.
What Are Private AI Agents?
A private AI agent is an AI agent that runs inside infrastructure you control, so prompts, data, and actions stay within your boundary instead of being sent to a shared public service. The word private is doing real work there. It does not describe the model's intelligence or the vendor's privacy policy. It describes a physical and logical fact: where the data sits while the agent is reasoning over it, and who can reach it while that happens.
That distinction gets lost because most agent demos run on someone else's cloud. The agent reads a document, calls a tool, writes a result, and the whole loop happens on infrastructure you do not own and cannot audit at the packet level. For a marketing draft, that is fine. For a customer's financial records, a patient file, or an engineering drawing covered by a contract, the same loop quietly moves regulated data across a boundary your compliance team is supposed to defend.
The market is moving fast enough that this question is no longer theoretical. Stanford's 2025 AI Index Report found that 78% of organizations used AI in 2024, up from 55% the year before. Adoption that steep means agents are touching production data inside companies that never deliberately decided where that data should live.
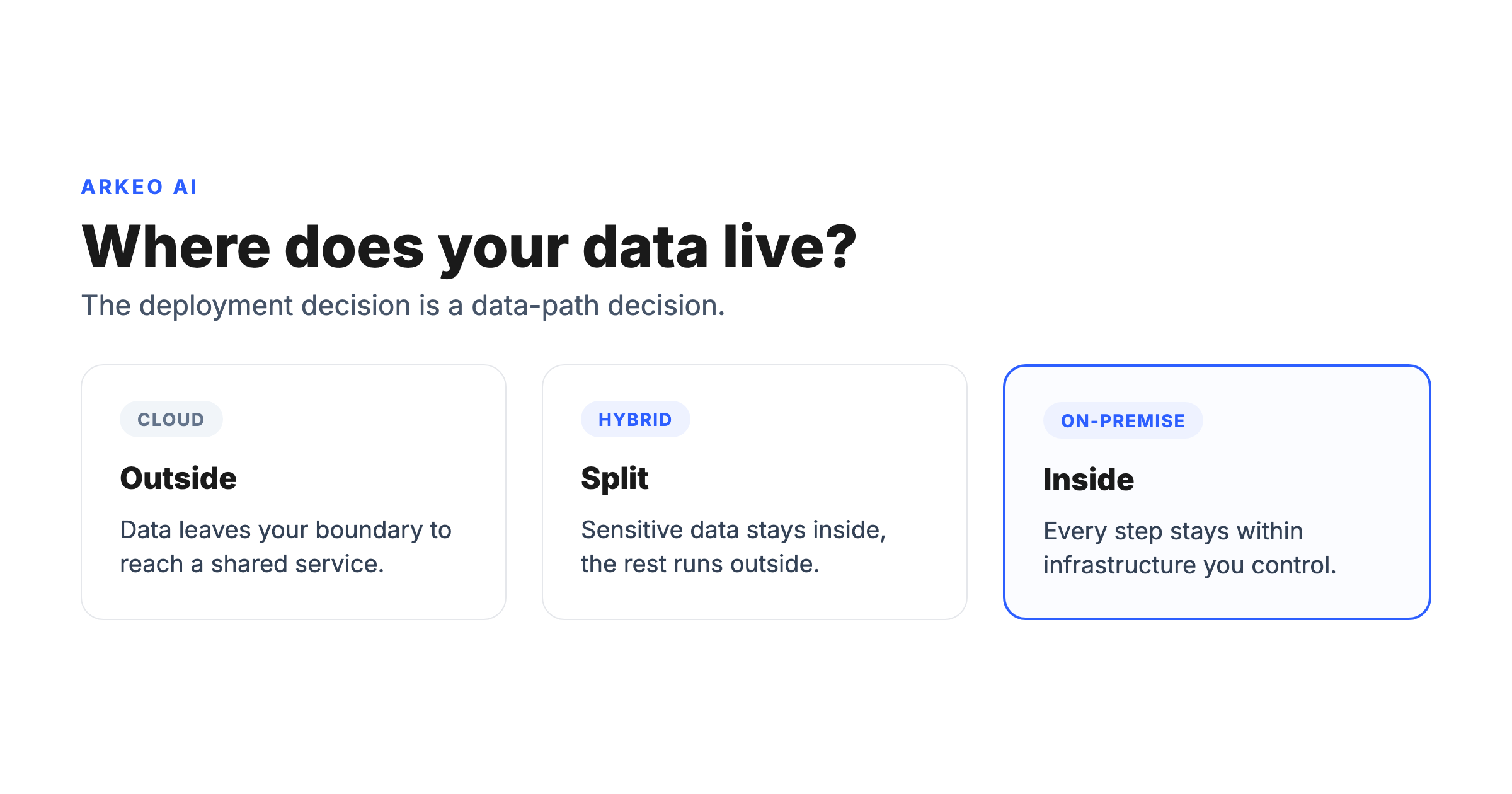
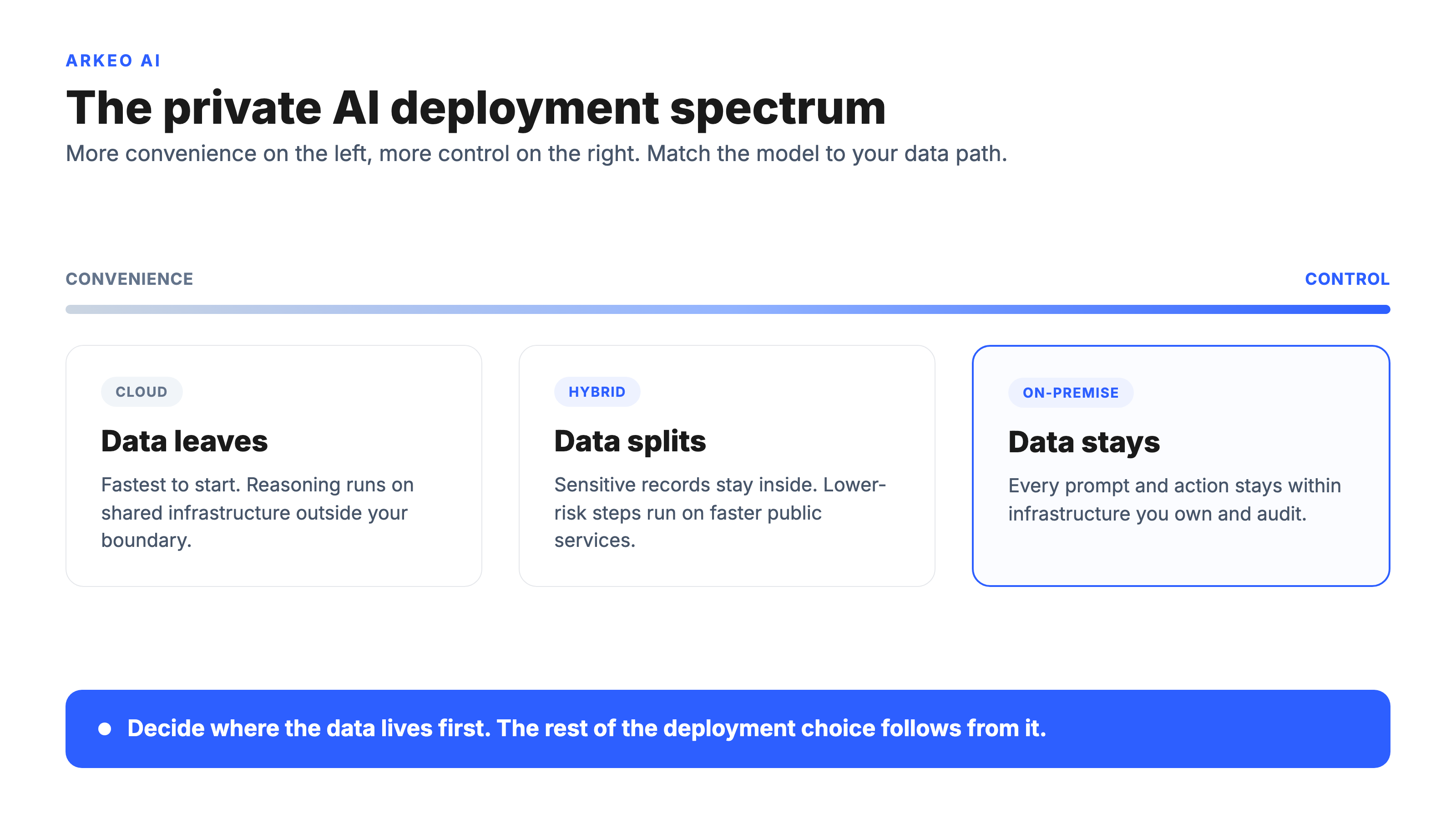
How Do Private And Public Deployment Actually Differ?
Public deployment means the agent's reasoning runs on a shared multi-tenant service. You send a request, the provider's infrastructure processes it, and you trust the contract and the configuration to keep your data segregated. Private deployment means the reasoning runs on infrastructure dedicated to you: your own servers, a private cloud tenancy, or a hybrid arrangement where the model runs in your boundary even if some orchestration sits outside it. In practice the private path usually runs an open-weight model such as Llama or Mistral on hardware you control, rather than calling out to a hosted commercial model. That choice is what keeps the reasoning inside the boundary, and it is also why a private deployment needs dedicated GPU-backed servers and a larger up-front setup than a cloud subscription that bills per request.
The honest version most vendors skip is that this is a tradeoff, not a free upgrade. Public services are faster to start, cheaper to run at low volume, and patched for you. Private deployment gives you control and data residency but you carry more of the operating weight. The deciding factor is rarely cost. It is the data path: which systems the agent reads from, what it writes back to, and whether any step in that loop carries records that are not allowed to leave.
Consider a regional insurance back office. An agent built to triage incoming claims has to read scanned medical reports, pull policy history from a core system, and write a recommendation into the case file. Every one of those steps touches data that, in a public deployment, would have to leave the building and traverse a third party's infrastructure to reach the model. The same workflow on a private deployment never lets those medical reports cross the boundary. Same agent, same task, completely different risk posture, decided entirely by where the data path runs.
| Factor | Cloud (public) | Hybrid | On-premise |
|---|---|---|---|
| Where data lives | Provider's shared infrastructure | Sensitive data inside, rest outside | Entirely inside your boundary |
| Control and audit | Contract-level, limited visibility | Strong over the private portion | Full, packet-level if you want it |
| Cost profile | Low to start, scales per use | Moderate, mixed model | Higher upfront, predictable later |
| Speed to start | Fastest | Moderate | Slowest, phased setup before go-live |
| Maintenance | Handled by provider | Shared responsibility | Yours to own and patch |
| Best for | Low-sensitivity, fast pilots | Mixed-sensitivity workflows | Regulated or proprietary data |
This comparison is the asset worth bookmarking. Most deployment debates stall because people argue model quality when the real variable is the row labeled where data lives. Decide that row first and the rest of the table tends to settle itself.
When Do Private AI Agents Actually Make Sense?
Most businesses assume private deployment is overkill, a luxury for banks and hospitals that everyone else can skip. That belief is wrong, and it is wrong in a specific way: it confuses how famous your industry's regulation is with how sensitive your actual data paths are. A 30-person engineering firm with proprietary client drawings has a sharper exposure than a large consumer brand running marketing agents on public infrastructure. Private deployment makes sense in three concrete situations.
The first is sensitive or regulated data. If the agent's workflow touches health records, financial detail, personal identifiers, or contract-bound client material, the question is no longer convenience. It is whether that data is permitted to leave your boundary at all. IBM's Cost of a Data Breach 2025 report found that 1 in 5 breached organizations cited a breach tied to shadow AI, which added roughly $670,000 to the average breach cost. Shadow AI is what happens when staff route sensitive data through public tools because no sanctioned private path exists.
The second is strict permissions and audit. A private deployment lets you scope exactly which systems an agent can read, which it can write to, and who is allowed to invoke it, with a log of every action. That matters more than people expect, because trust in autonomous systems is fragile. Capgemini's research on agentic AI found that trust in fully autonomous agents fell from 43% to 27% in a single year, and that fewer than 1 in 5 organizations report high data and technology maturity for running agents. Permissions and audit are how you earn back the trust the market is losing.
The third is integration constraints. Some of the systems an agent needs to touch simply cannot expose themselves to a public service: an air-gapped manufacturing system, a legacy core that lives behind the firewall, an ERP that contract terms forbid you from replicating externally. In those cases the deployment model is not a preference. It is a precondition for the agent existing at all.
Map your data paths before you pick a model
The free assessment traces which systems your priority agents would touch and flags the records that cannot leave your boundary, so you choose deployment from evidence instead of instinct.
Book Your Free AI Assessment →
What Are The Real Tradeoffs Of Private Deployment?
Here is the part a brochure leaves out: private deployment is harder, not just safer. The honest tradeoff lives across four dimensions, and pretending otherwise sets up a failed project.
Control is the dimension you gain. You decide where data sits, who reaches it, and how every action is logged. That control is the entire reason to go private, and it is genuinely valuable when your data paths carry sensitive records. IBM's same report found 13% of organizations reported breaches of AI models or applications, and 97% of those lacked proper AI access controls. Control is not abstract. It is the thing that was missing in nearly every one of those breaches.
Cost is the dimension that shifts shape. Public services are cheap to start and scale with use. Private deployment carries more upfront investment in infrastructure and setup, then becomes more predictable over time. The mistake is comparing only the starting price. The right comparison is total cost across the agent's working life, including the cost of a breach you avoided.
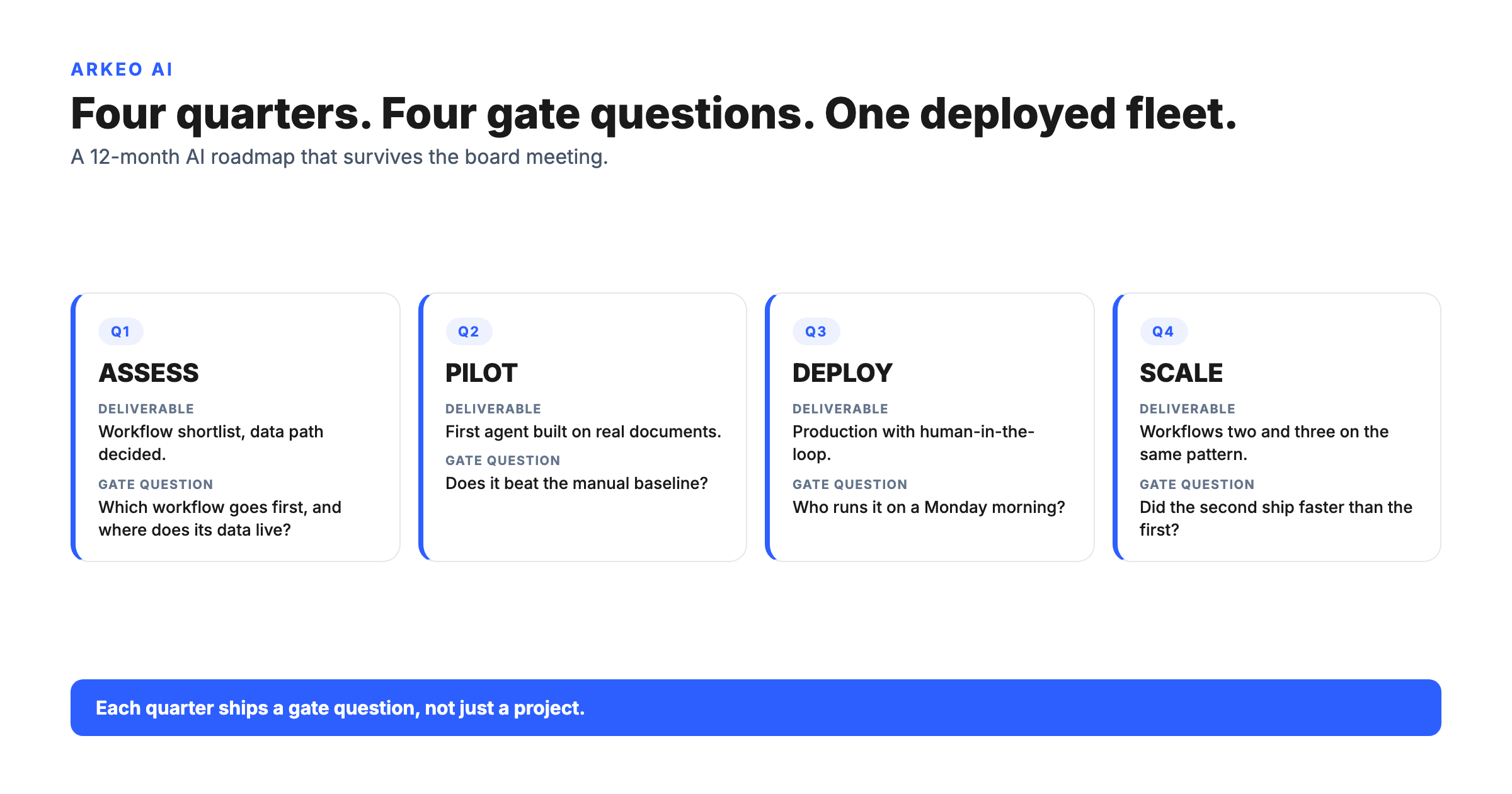
Speed is the dimension you trade away at the start. A private or on-premise workflow agent typically reaches production in 8 to 12 weeks, and the range is easier to trust when you see where the weeks go. The first phase is discovery and data-path mapping: cataloging which systems the agent reads and writes, and flagging the records that cannot leave the boundary. The second is integration and permissions: wiring the agent into those systems behind the firewall and scoping exactly what it is allowed to touch. The third is hardening and review: testing against real cases, tightening access controls, and a final review before the agent runs against live data. Cloud and off-the-shelf options compress that into days because the platform is pre-built, but they get there by sending data outside your boundary. That is the trade in one sentence: weeks of setup in exchange for never letting the data leave.
Maintenance is the dimension you inherit. On a public service the provider patches the model and the infrastructure. Run it privately and that responsibility is yours, which is why deployment should be matched to the team that will actually own it. This is the same logic that governs whether a workflow belongs to a general-purpose tool or a purpose-built one, the question explored in Arkeo's guide to enterprise AI agents and to building custom AI agents for a specific operation.
How Should You Decide Between Cloud, Hybrid, And On-Prem?
Start with the data, not the deployment. List the workflows you actually want an agent to run, then trace the data path for each: which systems it reads, which it writes, and whether any record in that loop is regulated, contract-bound, or otherwise not allowed to leave. That single trace decides more than any feature comparison.
Picture a mid-size accounting practice weighing an agent to prepare year-end working papers. The agent would pull from the document store, the practice-management system, and a folder of client bank statements. The first two are tolerable on a public service. The third is not, because those statements carry client financial detail that a partner would never agree to send outside the firm. A purely public deployment is off the table the moment that folder enters the data path. A hybrid model, where the sensitive folder stays inside and the lower-risk steps run elsewhere, becomes the obvious answer, and one permission scope has to be narrowed so the agent can read the statements without being able to export them. The deployment decision was made by the messiest piece of data in the workflow, not by the model.
From there the pattern is consistent. Low-sensitivity, exploratory work fits cloud. Mixed workflows, where some steps are sensitive and some are not, fit hybrid. Regulated or proprietary data that cannot leave fits on-premise. Deployment choice then flows back into workflow design itself: it shapes which steps the agent is allowed to automate, how permissions are scoped, and how much autonomy your risk tolerance permits. None of this replaces the broader question of where agents fit your operation, which Arkeo's pillar guide to AI agents for business addresses end to end. Private deployment is one answer to that question, chosen when the data path demands it.
It is worth saying plainly that most organizations are not ready to make this call on instinct. IBM's report found 63% of breached organizations had no AI governance policy or were still developing one. If governance is still forming, the deployment decision should be made deliberately, against the actual data, rather than defaulting to whatever was fastest to switch on. A free AI Assessment is the structured way to make that call: it maps each priority workflow against its real data path before any model is recommended, which is the same mapping that turns into the Arkeo Operating System a client eventually runs.
Choose deployment from evidence, not defaults
The free assessment maps your priority workflows, traces each data path, and recommends cloud, hybrid, or on-premise per workflow, so the model fits your risk instead of your vendor's roadmap.
Book Your Free AI Assessment →