Category
AI Agents vs ChatGPT: Which Is Safer?

Last updated: May 2026
Your team is already pasting contracts, financials, and source code into ChatGPT to get work done faster. The productivity is real. So is the problem: every one of those prompts sends proprietary data out of your network and onto infrastructure you do not control. Arkeo AI was founded in 2023 by an operator with 25 years of business experience and 3 years spent deploying AI agents in production, including the private agent workforce that runs Arkeo's own operations. That vantage point makes the security question unavoidable, so this breakdown answers it directly.
Quick Answer: AI Agents vs ChatGPT
• ChatGPT: A multi-tenant cloud service. Your prompts and outputs leave your network and are processed on shared, vendor-owned infrastructure.
• Private AI agents: A dedicated AI workforce deployed inside your own firewall, where data never leaves the building and you own the audit trail.
• Which is safer: For regulated records, proprietary IP, or sensitive operational data, private AI agents are the safer architecture because data sovereignty is built in, not promised in a contract.
• Cost shape: ChatGPT bills per token and rises with usage. Private infrastructure is a fixed cost that flattens as your team scales.
The market is loud with hype about AI assistants, and most of it skips the only question that matters to an operator handling sensitive data: where does the data physically go, and who can read it once it gets there? The honest answer separates a cloud tool you rent from a workforce you own. A free AI assessment maps where AI actually fits your operation before anything sensitive leaves the building, and the sections below explain why that mapping step matters.
The confusion is understandable, because the two things look identical in a browser tab. A useful first distinction comes from the vendor itself: when OpenAI introduced its agent capability, it described software that can navigate websites, run code, and complete multi-step tasks on a user's behalf rather than simply answering a question. That is the leap that turns a chatbot into an agent. A chat reads a prompt and writes a reply. An agent takes actions inside your systems, which means it needs access to your data, your tools, and your accounts. The convenience is obvious. So is the new surface area for risk.
What Is the Real Difference Between ChatGPT and AI Agents?
The core difference is ownership: ChatGPT is a multi-tenant cloud service you rent, while a private AI agent is a dedicated software workforce you run on your own infrastructure. Both can answer questions and complete tasks. Only one keeps your data inside a boundary you control.
ChatGPT, whether accessed through the web app or the API, processes your inputs on OpenAI's servers, shared across millions of other users. You do not control the model, the hardware, or the path your data travels. Private AI agents flip that arrangement. Built and managed for your specific operations through a structured Assess, Deploy, Manage methodology, they run on hardware you control, follow update schedules you set, and produce audit logs you own.
This distinction is no longer academic. Demand for agents is real and accelerating: a 2025 survey found that most executives are already using AI agents in their organizations, with deployment moving from pilots into core workflows. As that happens, the question shifts from whether to adopt agents to how to adopt them without handing core operational data to infrastructure you cannot see.
This is also where a common assumption falls apart. Most businesses believe an enterprise ChatGPT contract makes the data question go away. It does not. A contractual promise that your data will not be used for training is a policy commitment, not an architectural guarantee. The data still leaves your network, still lands on third-party disks, and still depends on a vendor honoring its own terms. Policy can change. Physics does not.
Security and Data Sovereignty: Where Does Your Data Actually Go?
The most immediate threat for mid-market companies right now is shadow AI. Employees bypass approved workflows and use personal ChatGPT accounts to process spreadsheets, review code, and analyze financial summaries. That creates IP leakage that IT cannot see, track, or prevent, because it never touches a system IT manages. The cost of getting this wrong is now measurable. IBM's Cost of a Data Breach research for 2025 found that 13 percent of organizations reported breaches of AI models or applications, and 97 percent of those lacked proper AI access controls. The pattern is consistent: the breaches are not exotic model attacks, they are ordinary access-control gaps around tools that quietly accumulated sensitive data.
Even with an enterprise agreement and clean API usage, the public-cloud model requires your operational data to leave the building. It travels across the internet, gets processed on third-party servers, and returns. For a firm handling engineering schematics, legal files, or regulated client records, that transmission is the security event, regardless of how the contract is worded.
A private deployment removes the transmission entirely. When the language model and the agent software both run inside your firewall, on hardware you own, your data never leaves the building during inference or training. This is the model Arkeo deploys, and the same model Arkeo uses internally. Arkeo uses what it sells, which is why the data-path question is treated as the first design decision, not a feature to bolt on later.
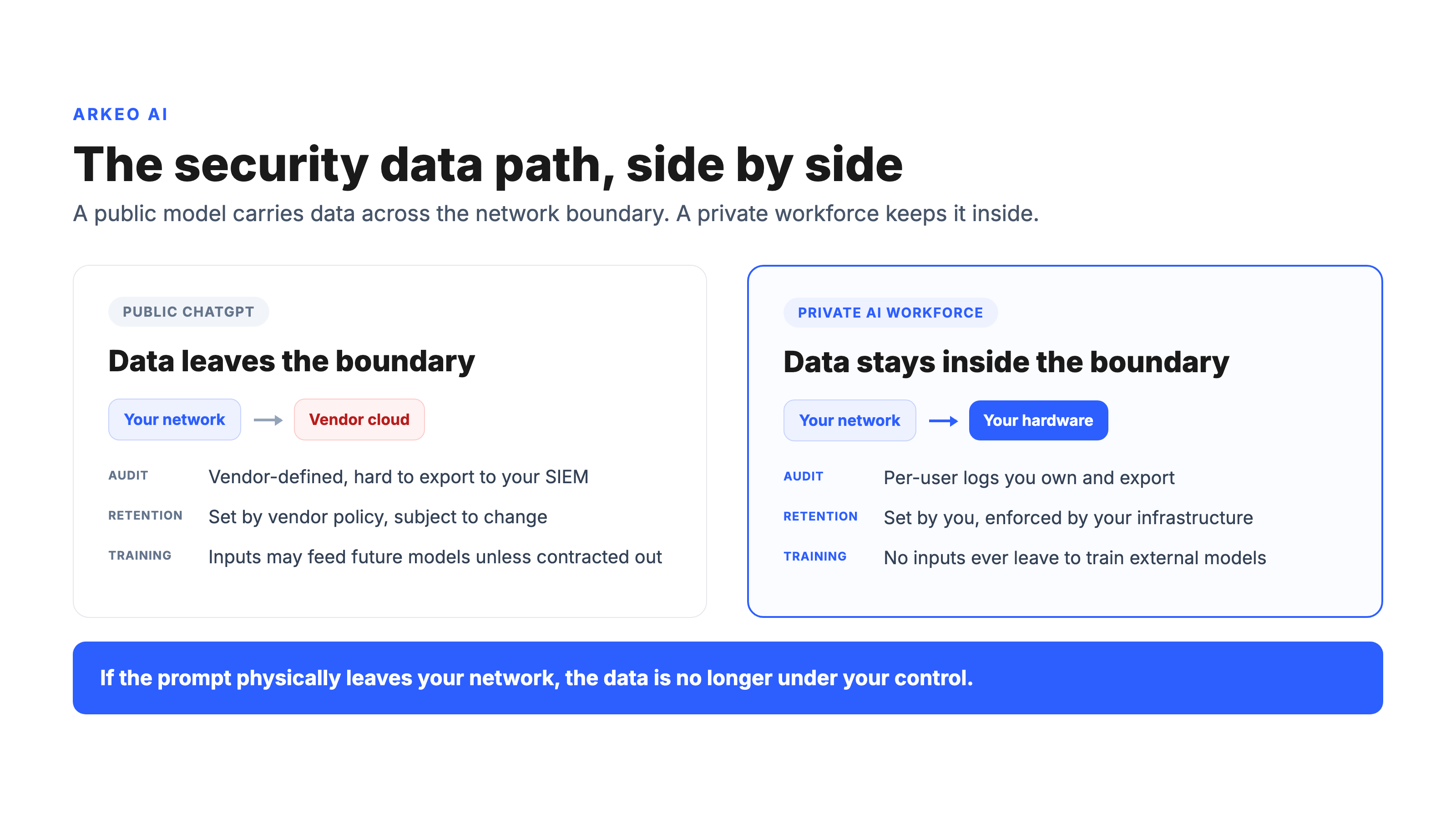
The blunt truth a vendor brochure will not print: a public AI agent is only as private as the weakest link in a chain of servers, sub-processors, and retention policies you cannot inspect. Insist on concrete answers to three questions before any pilot. Where does the prompt physically run? How long are prompts and outputs retained, and are they used to train future models? Is there a forensic-grade, per-user audit log you can export to your own systems? If the answers are vague, the data is not under your control.
Consider an explicitly hypothetical example to make the stakes concrete. Picture an engineering firm whose project lead pastes a confidential bid package into a public chatbot to summarize it before a deadline. The summary is excellent and the deadline is met. The bid specifications now also sit in a log on infrastructure the firm does not own, with no record of who sent them or how long they persist. Nothing visibly broke. The exposure is silent, which is exactly what makes it dangerous.
See where AI fits your operation
The free assessment maps which workflows are safe for public AI and which need a private deployment, with a concrete data-sovereignty plan you can act on.
Book Your Free AI Assessment →
Who Can See Your Data, and Can You Prove It?
Security is not only about whether data leaves the building. It is about whether you can prove who touched it, when, and why, long after the fact. This is the audit-trail question, and it is where the public and private models diverge most sharply. When a regulator, an insurer, or a client's security team asks for evidence of how their data was handled, the answer cannot be a vendor's assurance. It has to be a record you hold.
With a public chatbot, the audit trail belongs to the vendor. You may receive a workspace-level export, but it is shaped by what the vendor chooses to expose, retained on the vendor's schedule, and difficult to feed into your own security tooling. You cannot reconstruct, with certainty, that a specific employee sent a specific file to a specific model on a specific date and that the data was deleted afterward. The record of your own activity is mediated by a third party.
With a private deployment, the audit trail is yours by construction. Every prompt, every action an agent takes, and every document it reads is logged on infrastructure you own, in a format you can export to your own SIEM and retain on your own schedule. This is the practical heart of governance frameworks. The NIST AI Risk Management Framework is built around the ability to map, measure, and manage AI risk across the system lifecycle, and you cannot measure or manage what you cannot see. Ownership of the log is what makes the rest of a governance program enforceable rather than aspirational.

The difference becomes concrete the day something goes wrong. If a sensitive file is mishandled, a public-cloud setup leaves you reconstructing events from partial vendor exports and hoping the retention window has not already closed. A private setup lets your own team query a complete, immutable record and answer the question definitively. One model leaves you explaining a gap. The other lets you produce evidence.
How Do Costs Compare: Per-Token Billing vs Fixed Infrastructure?
ChatGPT and other cloud models bill per token. You pay for every word sent to the API and every word generated in response. This produces the token trap: the more useful your agents become and the more tasks they handle, the more you pay. Cloud pricing penalizes the exact thing you want, which is operational scale.
A rough, illustrative anchor makes the shape clear. A 25-person team on a seat-priced public plan pays roughly $750 a month at flat per-seat pricing before a single agent API call is made. Add agent-level API usage at scale, where each automated task may consume hundreds of thousands of tokens, and that bill climbs quickly and unpredictably with adoption. By contrast, private infrastructure for a comparable team is a one-time capital or hosting cost that amortizes over years rather than recurring per word. These figures are illustrative, not a quote, and the exact numbers depend on usage and hardware. The point is the direction of travel: public pricing rises with success, while private cost holds steady and the per-task figure falls as more of the team uses it.
A private AI workforce runs on fixed-cost infrastructure. You pay for server capacity, not individual words, so costs stay predictable month over month. As volume grows, your per-task cost falls, which means return on investment improves as adoption spreads rather than eroding. Variable pricing looks cheap in a demo and turns expensive the moment a full team relies on it. Fixed cost inverts that math once usage becomes steady.
Which Is Safer for Proprietary Business Data?
For sensitive, regulated, or competitively valuable data, private AI agents are the safer choice, and the reason is structural rather than reputational. Safety here is not about which vendor is more trustworthy. It is about whether the data ever leaves a boundary you can audit. A public model can be operated responsibly and still expose you, because the architecture requires transmission off your network. A private deployment makes the safe outcome the default.
The table below maps the comparison an operator actually has to make, across the dimensions that decide whether a tool is fit for sensitive work.
| Dimension | ChatGPT (public cloud) | Private AI agents |
|---|---|---|
| Data control | Data leaves your network on every prompt and action | Data stays inside your firewall during inference and training |
| Audit trail | Limited, vendor-defined, hard to export to your SIEM | Per-user logs you own and export to your own systems |
| Retention | Set by vendor policy, subject to change | Set by you, enforced by your own infrastructure |
| Data sovereignty | Promised contractually, not guaranteed architecturally | Guaranteed by where the system physically runs |
| Cost shape | Per-token, rises with usage | Fixed infrastructure, flattens as you scale |
None of this means public AI has no place. For low-sensitivity drafting and research it is fast and effective, and the practical path is usually a mix. The discipline is knowing which data class each task belongs to and routing accordingly. For teams trying to standardize that decision, it helps to understand how purpose-built agents differ from a general assistant, how a ChatGPT agent builder fits into early workflows, and what real-world operators report about running things in ChatGPT agent mode before committing sensitive processes to it.
While public ChatGPT agents are genuinely useful for general drafting and research, they create real security and cost exposure the moment they touch core business systems. Once an agent reads your CRM, your file server, or your codebase, the architecture underneath it stops being a convenience and becomes a governance decision.
How Do You Move From ChatGPT to a Private AI Workforce?
The transition is a sequence, not a rip-and-replace. Arkeo maps the current state to find bottlenecks and the data each workflow touches, then captures 30-to-90-day easy wins with prompts and approved tools, identifies the top mid-term agent opportunities, and lays out a long-term architecture toward a private AI operating system. The Assess phase output is concrete rather than abstract: a workflow inventory tagged by data sensitivity, a shortlist of automations ranked by value and risk, and a recommended architecture sized to the team. The blunt reality is that AI agents break and need real operational ownership, which is precisely why the Manage phase exists rather than ending at deployment. The goal is not to ban public AI, it is to give your team a private alternative that is at least as fast, so the secure path becomes the path of least resistance.
Map your data before you scale AI
The free assessment classifies your workflows by data sensitivity and shows exactly where a private deployment protects you, with no obligation.
Book Your Free AI Assessment →