Category
Self-Hosted AI Agents: When To Run Them Inside
Last updated: May 2026
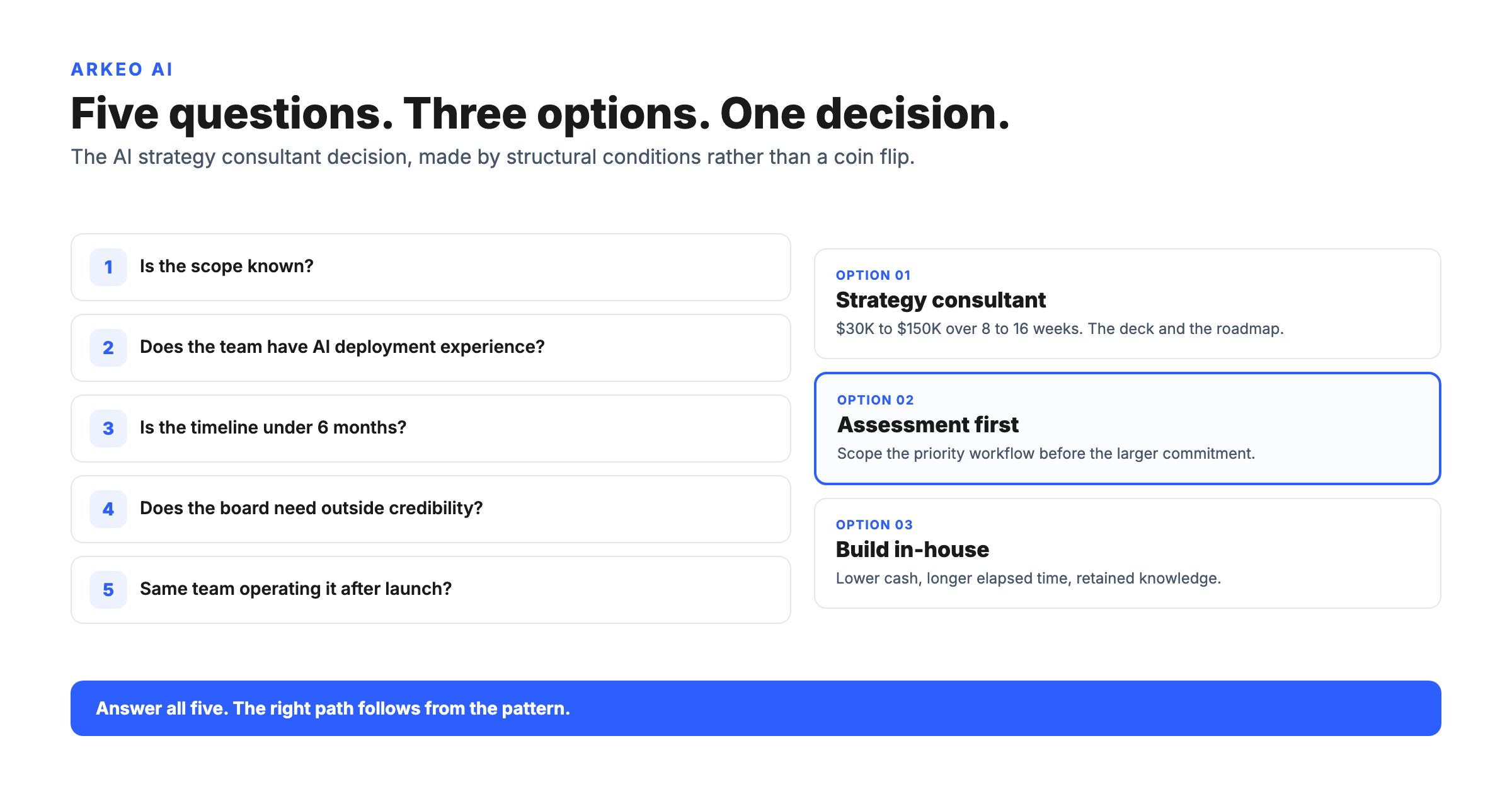
You want AI agents doing real work: clearing a queue, reconciling records, drafting and filing documents without a person babysitting every step. The harder question is where that work happens. The moment an agent stops answering questions and starts taking actions on your systems, you are deciding how much of your operation a piece of software gets to touch, and where your data sits while it does. Arkeo was founded in 2023 by operators with 25 years running real businesses, and has spent three years deploying agents in live operations, including its own. The lesson from that work is blunt: the model is rarely the hard part. The data path and the permissions are. If you want to map which workflows actually warrant an agent inside your walls, that is where this decision starts.
Quick Answer
• What they are: self hosted AI agents run on infrastructure you own or control, so the agent's reasoning, data access, and actions never leave your network boundary.
• When they matter: when an agent must touch sensitive or regulated data, act on systems behind your firewall, or operate under policy constraints a public platform cannot meet.
• The catch: you inherit the maintenance, the governance, and the blast radius if the agent acts wrongly.
• Why it matters: running an agent internally is a governance decision, not just a hosting choice. Decide it against your real workflows, not a vendor demo.
What Are Self-Hosted AI Agents?
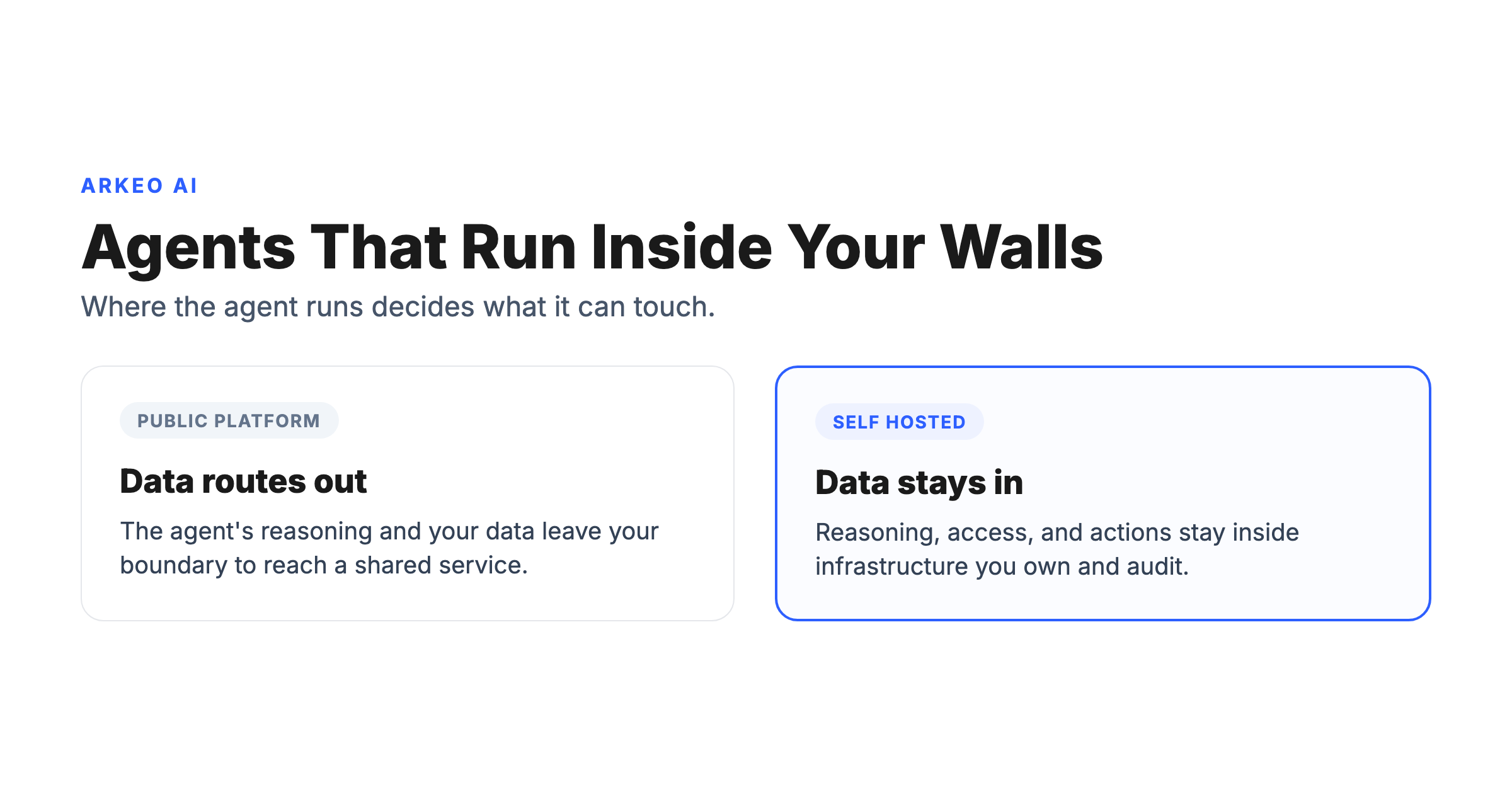
A self-hosted AI agent is an AI agent that runs on infrastructure your organization owns or controls, so its compute, memory, tool calls, and data access stay inside your network boundary instead of being routed to a third-party service. The distinction is not about how clever the model is or what a vendor's privacy policy promises. It is a physical and logical fact about where the work happens and who can reach the data while the agent is reasoning over it and acting on it.
That difference gets lost because most agent demos run on someone else's cloud. The agent reads a file, calls a tool, writes a result, and the entire loop executes on infrastructure you neither own nor can audit at the packet level. For a public marketing draft, that is fine. For a customer's financial record, a patient file, or a contract-bound engineering drawing, the same loop quietly carries regulated data across the boundary your compliance team is supposed to defend. A chat tool produces text a human reads and decides what to do with. An agent produces actions a system executes directly. That is the whole reason self hosting comes up: when software starts acting on your behalf, where it runs stops being a detail.
The scale of this is no longer hypothetical. Gartner projects that by 2028, 33% of enterprise software will include agentic AI, up from less than 1% in 2024, and that at least 15% of day-to-day work decisions will be made autonomously by agents, up from none two years earlier. Agents are about to be everywhere, which means a lot of companies are about to make this hosting decision by accident.
How Do Self Hosted Agents Differ From Public-Platform Agents?
A public-platform agent runs its reasoning on a shared, multi-tenant service. You send a request, the provider's infrastructure processes it, calls whatever tools you connected, and returns a result. You trust the contract and the configuration to keep your data segregated. A self hosted agent runs that same loop on infrastructure dedicated to you: your own servers, a private cloud tenancy, or a hybrid arrangement where the model and the sensitive data stay inside your boundary even if some orchestration sits outside it. In practice the self hosted path usually runs an open-weight model on hardware you control, rather than calling out to a hosted commercial model, and that single choice is what keeps both the data and the actions inside the perimeter.
The contrast that matters most is the data path. With a public-platform agent, every document the agent reads and every system it queries has to be exposed to that outside service for the agent to function. Company data is routed out. With a self hosted agent, the same documents and systems are reached from inside, and the full record of what the agent touched and did stays in logs you own.

This is also where the honest tradeoff lives, and most vendors skip it. Public platforms are faster to start, patched for you, and cheap at low volume. Self hosting gives you control, data residency, and a complete audit trail, but you carry the operating weight: model updates, infrastructure scaling, observability, and security patching all become yours. The deciding factor is rarely the monthly bill. It is the sensitivity of the data the agent must touch and how much of your operation it is allowed to act on.
When Are Self Hosted AI Agents Worth The Complexity?
Most businesses assume running agents internally is overkill, a luxury reserved for banks and hospitals that everyone else can skip. That belief is wrong, and it is wrong in a specific way: it confuses how famous your industry's regulation is with how sensitive your actual data paths are. A 30-person engineering firm sitting on proprietary client drawings can have sharper exposure than a large consumer brand running marketing agents on public infrastructure. Self hosting earns its complexity in three concrete situations.
The first is sensitive workflows. If an agent's job touches health records, financial detail, personal identifiers, or contract-bound client material, the question stops being convenience and becomes whether that data is permitted to leave your boundary at all. Data exposure, not model accuracy, is now the dominant concern: Thales reports that enterprises name exposure of sensitive data as their top worry in securing AI applications, and forecasts that by 2027 more than 40% of AI-related data breaches will trace to improper use of generative AI across borders. You can read the Thales analysis on the impact of AI on digital sovereignty for the full argument. Sovereignty has gone mainstream too: Deloitte's State of AI in the Enterprise 2026 report found 83% of companies now treat sovereign AI as important to their strategic planning and 77% factor a vendor's country of origin into selection decisions.
The second is system control. A self hosted deployment lets you scope exactly which systems an agent can read, which it can write to, who is allowed to invoke it, and a log of every action it takes. This matters more than people expect, because the failure data is unforgiving. IBM's Cost of a Data Breach 2025 report found that of the organizations that reported a breach of an AI model or application, 97% lacked proper AI access controls, and 63% either had no AI governance policy or were still developing one. You can review IBM's findings in their report on AI model breaches. Control is not abstract. It is the thing that was missing in nearly every one of those incidents.
The third is policy constraints. Some systems an agent needs to act on simply cannot expose themselves to a public service: an air-gapped operations system, a legacy core behind the firewall, an ERP whose contract terms forbid replicating its data externally. In those cases the hosting model is not a preference. It is a precondition for the agent existing at all.
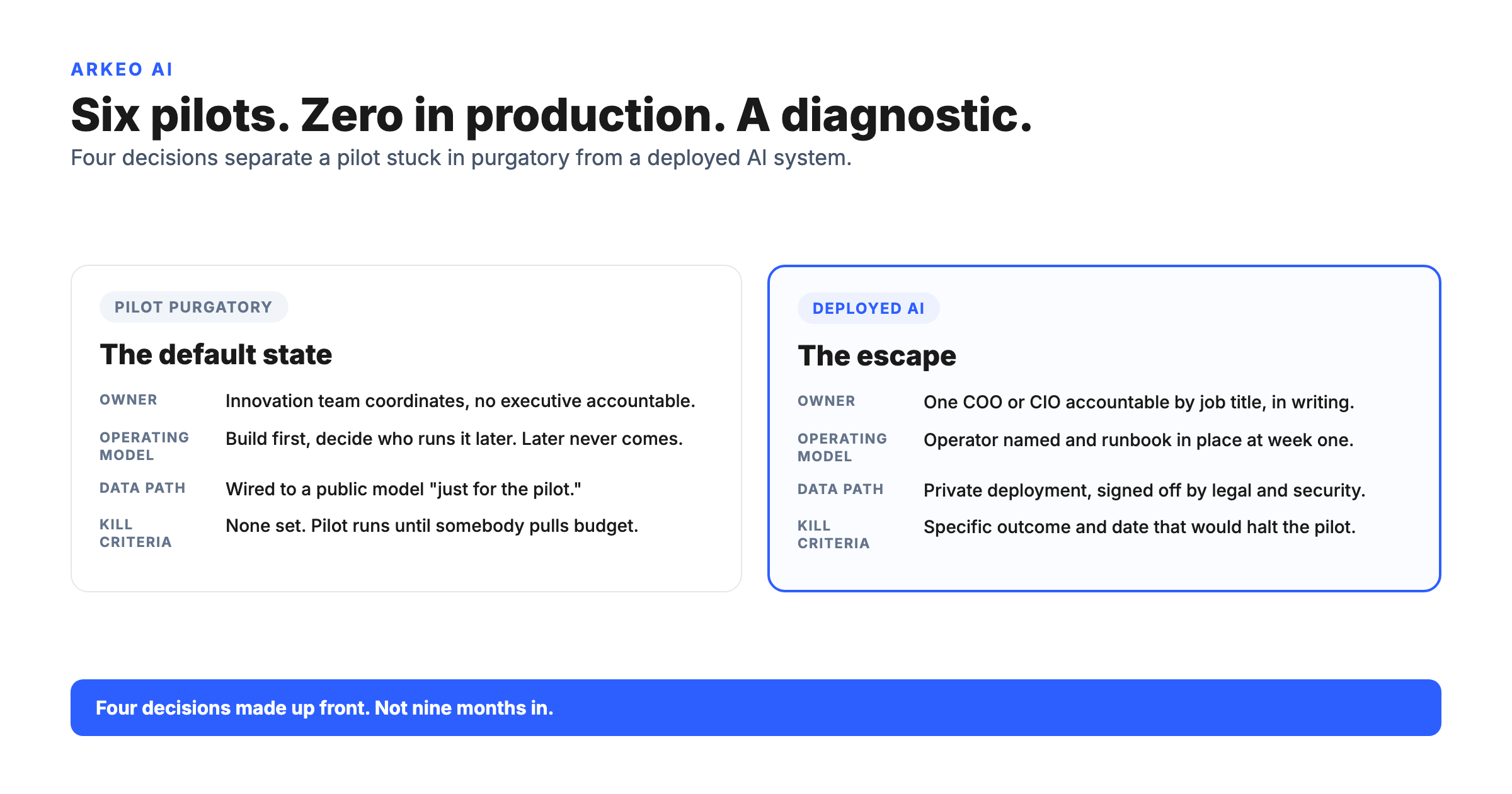
What Can Go Wrong With Self Hosted Agents?
Here is the part a brochure leaves out: AI agents break, and they break in ways chat tools never could. A chat tool that hallucinates produces a wrong sentence a human can catch. An agent that acts on a bad decision can delete the wrong file, fire the wrong API call, or push a misconfigured approval through three connected systems before anyone notices. The blast radius of an agent failure is proportional to the permissions it holds. Self hosting does not remove that risk. It puts the controls for managing it inside your reach, which is the entire point.
The market is already living this. Gartner predicts that more than 40% of agentic AI projects will be canceled by the end of 2027, driven by escalating costs, unclear business value, and inadequate risk controls. McKinsey's State of AI research tells the same story from the other side: the gap between the share of organizations experimenting with agents and the share that have a mature governance model for them is wide, and the experimentation is running well ahead of the governance. Deloitte puts a number on the gap, finding in its research on AI agents scaling faster than governance that only 21% of organizations have a mature governance model for agentic AI, leaving roughly four in five without the clear decision boundaries, real-time monitoring, and audit trails an autonomous agent demands. Three failure modes show up over and over, and each one has a control that contains it.
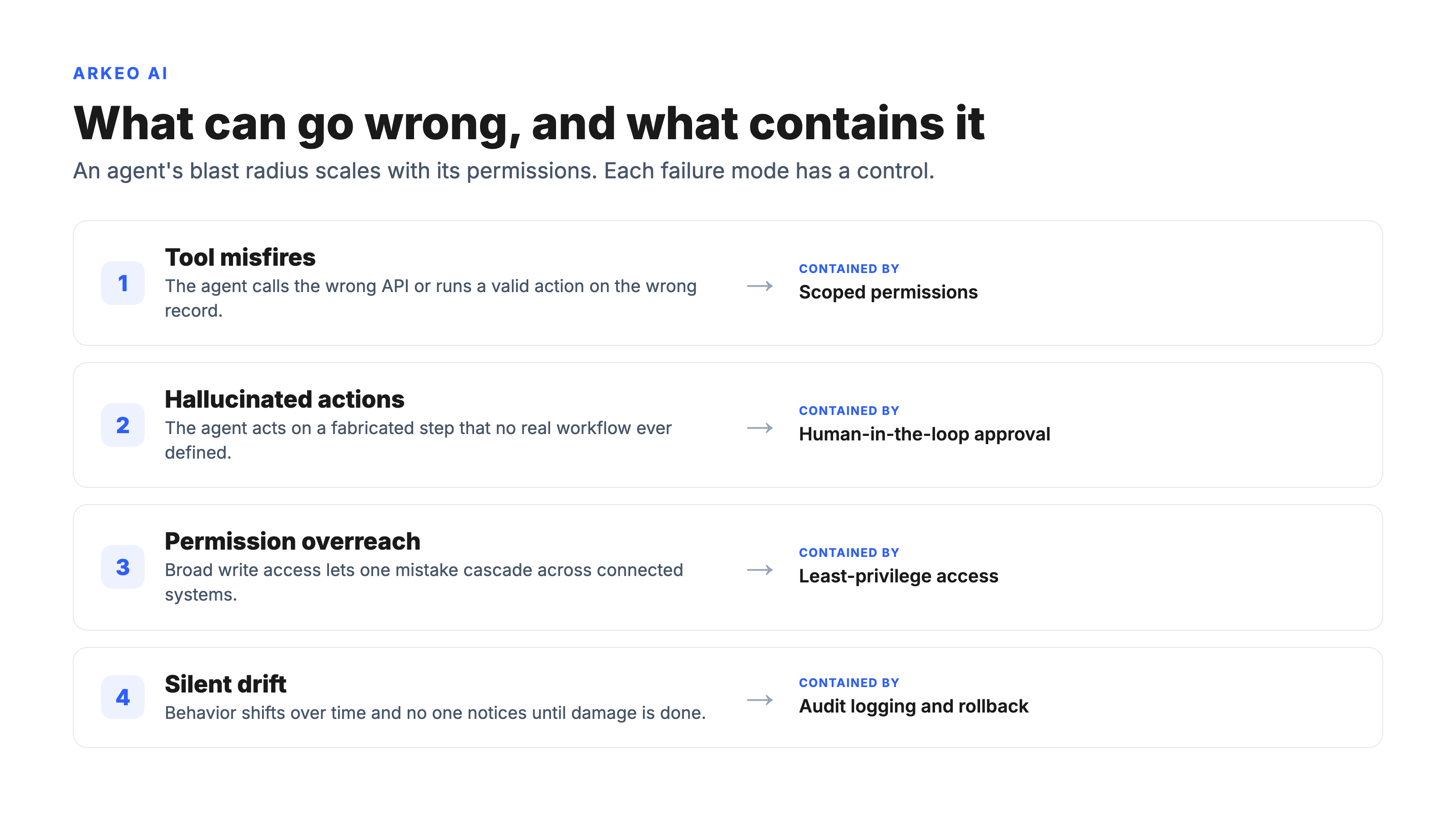
In Arkeo's own deployments the pattern is consistent: mapping an agent's permissions and data access takes longer than standing up the model itself. Choosing and running the model is the part that gets the attention, but the work that actually protects the business is the slow part nobody photographs, which is deciding exactly which systems the agent may read, which it may write to, and who gets to invoke it. Teams that rush that step are the ones who end up in the cancellation statistics.
The first is maintenance burden. Run an agent internally and you own the model updates, the scaling, the monitoring, and the security patching the provider used to handle. That overhead is justified when governance and data-residency requirements cannot be met any other way, but it is a real operational cost and it should be scoped honestly before anyone commits.
The second is weak workflows. Pointing an agent at a process that is undefined, undocumented, or constantly changing is how projects end up in that 40% cancellation statistic. An agent automates a workflow; it does not invent one. If a human cannot describe the steps, the inputs, and the approval points cleanly, the agent will encode the chaos rather than fix it.
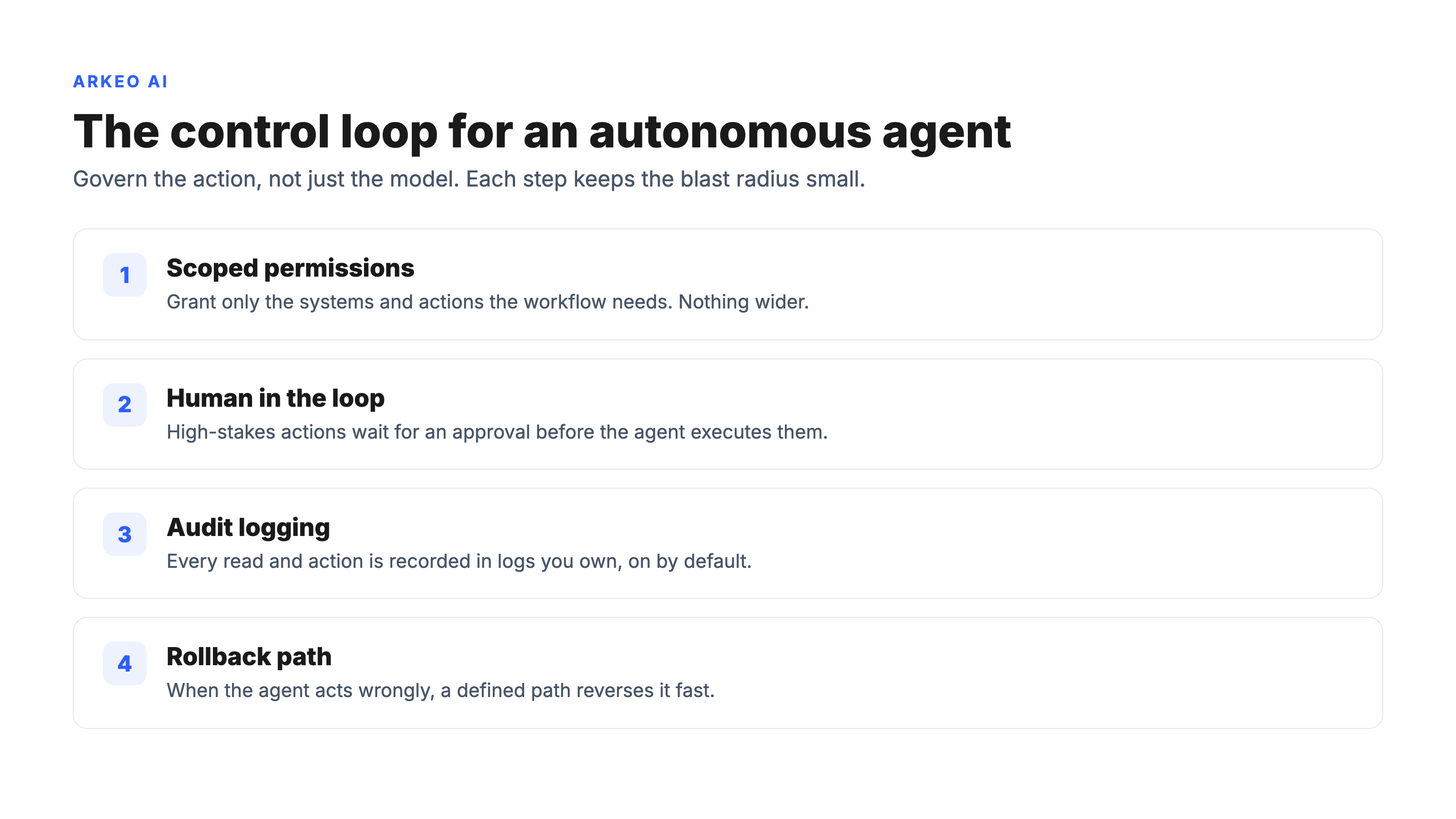
The third is unclear ownership. An autonomous agent acting on production systems needs a named owner, scoped permissions, human-in-the-loop checkpoints for high-stakes actions, audit logging on by default, and a rollback path for when it acts wrongly. Picture an operations team that hands a self hosted agent broad write access to its order system because narrowing the scope felt like extra work. The day it cancels a batch of legitimate orders, the absence of a rollback path and an action log turns a five-minute fix into a week of forensic reconstruction. That is a hypothetical, but it is the exact shape of failure the governance loop below is built to prevent.
None of these are reasons to avoid agents. They are reasons to govern them, and self hosting is what makes the governance enforceable rather than contractual.
Know the blast radius before you grant the access
The free assessment traces the data path and system access each priority agent would need, then flags where the permissions are too broad and which workflows warrant the controls of self hosting.
Book Your Free AI Assessment →
How Do You Decide Whether To Host Agents Internally?
Start with the data and the actions, not the hosting. List the workflows you actually want an agent to run. For each, trace two things: the data path (which systems it reads, which it writes) and the action scope (what it is allowed to change, and what the worst plausible mistake would cost). That trace decides more than any feature comparison. The realistic answer for most organizations is not all-or-nothing but hybrid: sensitive or regulated workflows run on internal infrastructure with strict controls, while lower-risk, non-proprietary tasks may use a managed cloud agent. The decision boundary is the sensitivity of the data the agent must touch.
The table below is the asset worth bookmarking, because most hosting debates stall when people argue model quality while the real variable is the row about what data and systems the agent touches.
| If the agent's workflow... | Public-platform agent | Self hosted agent |
|---|---|---|
| Touches regulated or contract-bound data | Routes that data outside your boundary | Keeps it inside, with full audit |
| Writes to systems behind the firewall | Often impossible or non-compliant | Reaches them from inside the perimeter |
| Is low-risk and non-proprietary | Fastest, cheapest path | Usually unnecessary overhead |
| Needs a complete action audit trail | Limited to provider-level visibility | Logged in records you own |
| Has no defined owner or rollback plan | Not ready for either model | Not ready for either model |
From there the pattern is consistent. Sensitive data plus action on internal systems points to self hosting. Low-sensitivity, exploratory work fits a public platform. Mixed workflows fit hybrid. The last row is the one most people miss: if a workflow has no owner and no rollback path, it is not ready for any agent yet, hosted however you like. That governance gap, not the hosting choice, is what sinks the projects in the cancellation statistic. The same control logic that decides where an agent runs also shapes how an individual assistant is scoped, a question Arkeo covers in its guide to deploying a private AI assistant, and it sits inside the broader hosting decision laid out in the pillar on self-hosted AI.
For first use cases, pick a workflow that is well-defined, valuable, and bounded: one with clear inputs, a clear output, and an action whose worst-case mistake is recoverable. Prove the governance loop on that before handing an agent anything that can damage a customer relationship. This is the same sequence Arkeo runs on its own operations. We use what we sell, and that internal stack of hosted agents is what becomes the Arkeo Operating System a client eventually runs. Most organizations are not ready to make this call on instinct, and they should not have to. A free AI Assessment maps each priority workflow against its real data path and action scope before any model or hosting model is recommended.
Ready to map your first agent? Start here
Book the free assessment and walk out with a workflow-by-workflow plan: which agents to build first, what each one should connect to, and whether it belongs inside your boundary or on a public platform.
Book Your Free AI Assessment →