Category
What Is an On-Premise LLM, and Does Your Business Need One?

If you have spent time looking into AI for your business, you have almost certainly encountered the term "LLM" at some point. Maybe in a trade publication, maybe in a conversation with someone in tech, maybe in a vendor pitch that left you more confused than when you started. The term gets used constantly, rarely explained, and often followed by a level of technical detail that is not useful if you are a business owner trying to decide whether this matters to you.
Here is the short version: an LLM is the engine underneath most AI tools your team already uses. An on-premise LLM is one that runs on your own infrastructure instead of a cloud provider's. Whether your business needs one depends on what you are doing with AI and what data you are feeding into it.
Quick Answer
- LLM: Large Language Model. The AI engine that reads and generates text. Powers ChatGPT, Copilot, Claude, and most business AI tools.
- On-premise LLM: An LLM that runs on servers you own or control. Your data stays in your environment.
- Who needs one: Businesses with sensitive data, compliance requirements, or proprietary processes they cannot process through a third-party cloud system.
- Who does not need one right now: Businesses using AI for low-stakes, low-sensitivity tasks where cloud tools are adequate.
What Is an LLM?
A Large Language Model is a type of AI system trained on very large amounts of text. During training, the model learns patterns in language: how words relate to each other, what follows what, what kinds of responses fit what kinds of questions. The result is a system that can read text, understand context, and generate coherent, relevant responses.
Every conversational AI tool you have used is built on an LLM or something similar. ChatGPT runs on GPT-4 and its successors. Microsoft Copilot runs on the same models. Claude runs on Anthropic's models. These are all variations of the same underlying technology.
What makes one LLM different from another is primarily size (how many parameters it has, which affects capability), training data (what it learned from), and fine-tuning (whether it has been further trained for specific tasks). A general-purpose LLM like the one behind ChatGPT has seen an enormous amount of text covering nearly every topic imaginable. A fine-tuned LLM trained on your company's SOPs, contracts, and historical reports has seen less data overall but is much more useful for your specific workflows.
What Does "On-Premise" Add?
When you use ChatGPT or Copilot, your prompts and the data you include in them travel to OpenAI's or Microsoft's servers, get processed, and a response comes back. That is the cloud model. Your data is off your infrastructure for the duration.
An on-premise LLM runs on servers you control. The model sits on your infrastructure. When an employee asks it a question or pastes in a document, that data never leaves your environment. The processing happens locally. The response comes back from your own server, not a vendor's.
The practical difference is significant for any business that handles:
- Client-specific operational data (O&G, construction, professional services)
- Proprietary pricing, formulas, or processes that represent real competitive value
- Regulated information subject to HIPAA, legal privilege, or industry-specific data residency requirements
- Contract terms, financial projections, or M&A information that could not appropriately be shared with a third party
For businesses that primarily use AI for low-sensitivity tasks (drafting marketing content, summarising public information, internal communication drafts with no confidential content), the cloud model may be perfectly adequate. The decision is not ideological. It is about what data you are actually using with the AI and what the consequences of that data leaving your environment would be.
Keep Your Data in Your Environment
Book a free AI Capacity Assessment. Find out if an on-premise LLM makes sense for your business and what deployment looks like in your specific situation.
When Does a Business Actually Need an On-Premise LLM?
The honest answer is: not always. Cloud AI tools are useful, fast to deploy, and adequate for many workflows. The case for an on-premise LLM is not that cloud AI is bad. It is that for specific businesses with specific data, keeping the model local is the more defensible decision.
Consider these situations:
You are in a regulated industry. Healthcare, legal, accounting, oil and gas, and certain areas of construction and manufacturing all involve data subject to regulations that limit where it can be processed and stored. If your AI workflows involve patient records, client legal matters, financial reporting, or safety compliance documentation, cloud processing creates compliance exposure you may not have fully mapped.
Your employees are already using cloud AI with company data. 76% of AI experiments never reach production. But many individual employees have quietly built AI into their daily workflows using personal accounts or unapproved tools. If that is happening at your company, your proprietary data is likely already moving through systems you do not control. An on-premise deployment does not fix past exposure, but it gives you a governed alternative that employees will actually use because it is faster and better configured for your specific work.
Your competitive advantage lives in your processes. Some businesses are built on operational IP that has genuine value: estimating approaches in construction, compliance frameworks in O&G, client methodology in professional services. Running those processes through a third-party AI system means that methodology is now part of someone else's training data universe, even if imperfectly. Keeping it on-premise keeps it yours.
You are planning to scale AI use significantly. Cloud AI costs scale with usage. If AI becomes genuinely embedded in your operations (which is the point), you will be generating very high volumes of API calls. The economics of on-premise deployment improve substantially once you reach meaningful usage volume.
What You Do Not Need to Manage Yourself
The concern most business owners have about on-premise AI is the technical overhead. Who maintains it? Who updates it? What happens when something breaks?
These are legitimate concerns about DIY deployment. They are not concerns about managed deployment.
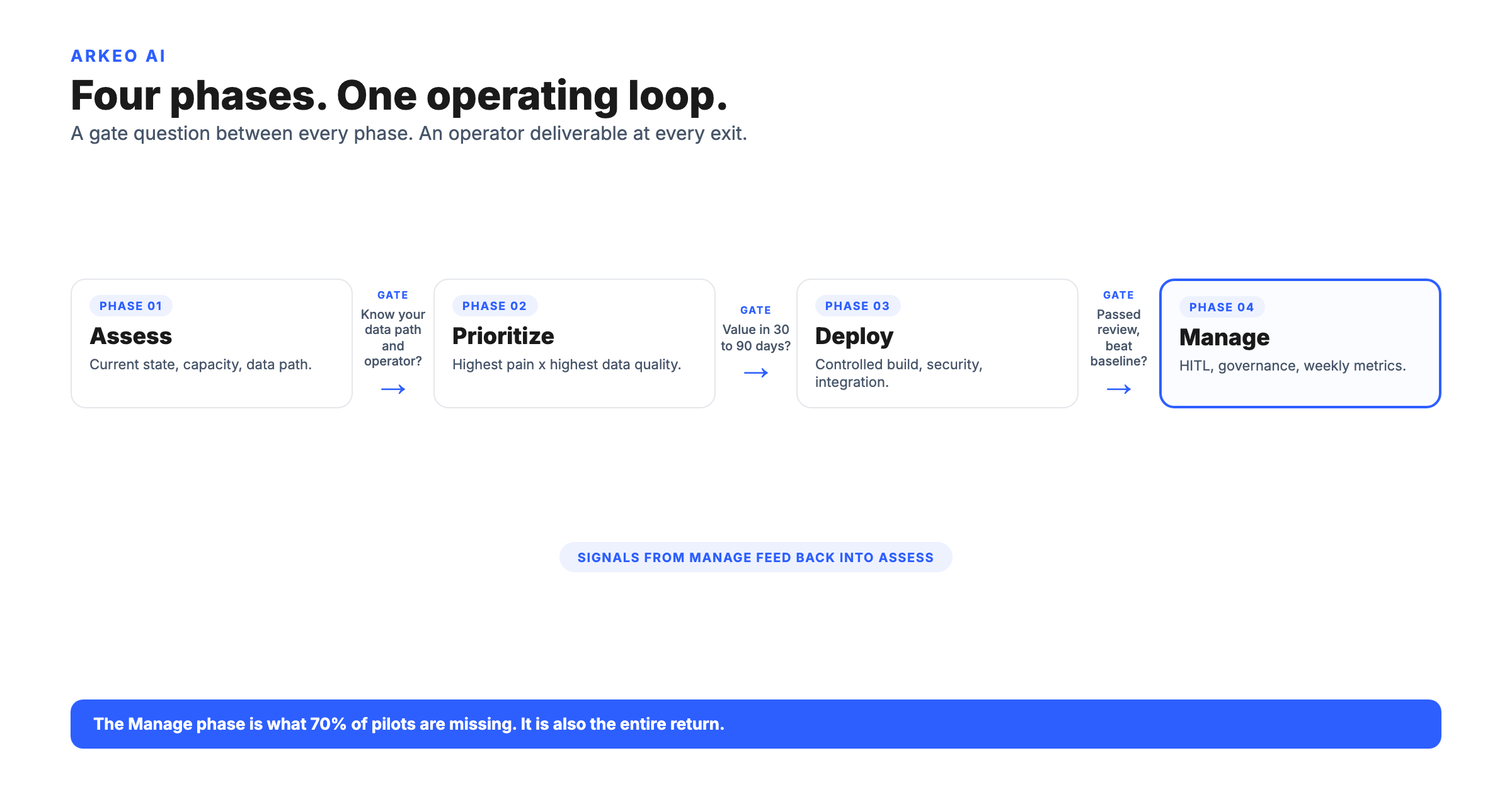
Arkeo has been building and running AI agents in production since 2023. When we deploy an on-premise LLM for a client, we handle infrastructure setup, model selection and configuration, integration with existing systems, and ongoing managed operations. The client gets a working system. They do not get a new technical project to manage.
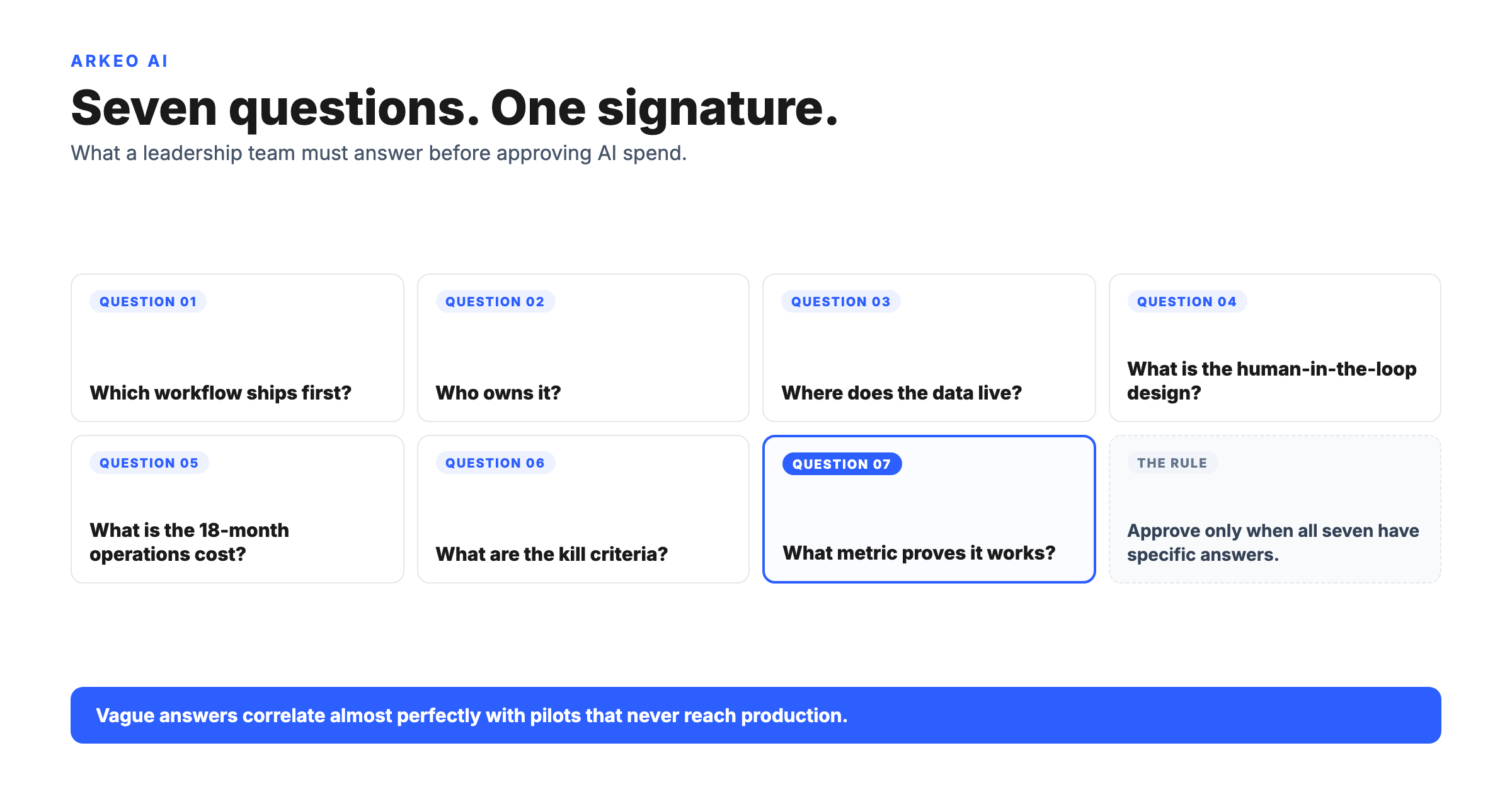
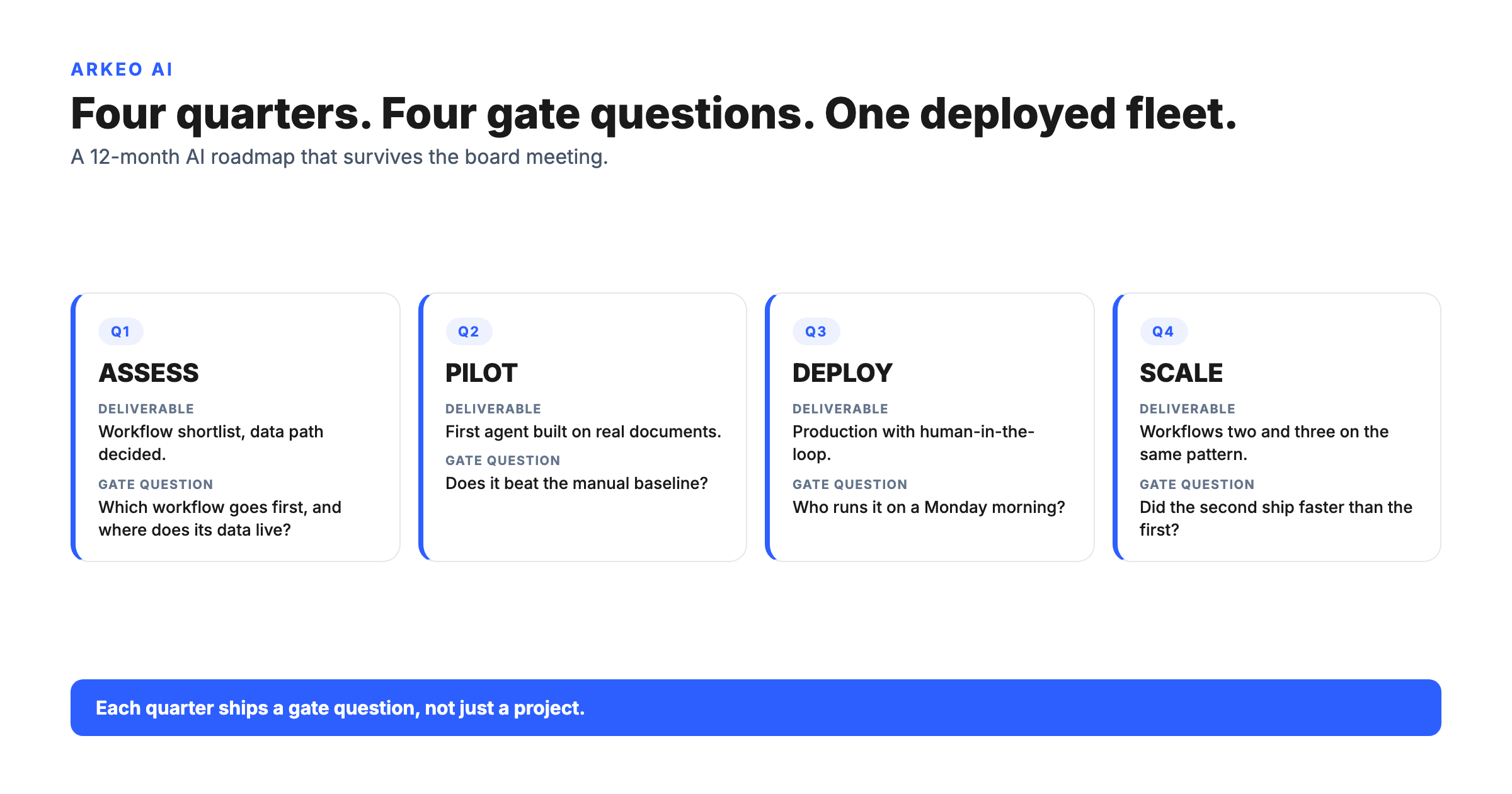
The Core tier is live in under one week. It deploys a private AI assistant trained on your company documents, SOPs, and policies, running on your infrastructure. No integrations required, no IT project, no data scientist needed. At $6,500 activation and $1,500 per month, it is a known cost for a working system, not a budget estimate for a development project.
The Connected tier adds API integrations with your CRM, email, calendar, and other systems, typically taking 30 to 45 days to deploy. The Orchestrated tier builds a multi-agent system across departments, taking 60 to 90 days.
In every case, the technical work is Arkeo's. The business outcome is yours.
On-Premise LLM vs Cloud AI: The Right Question to Ask
The wrong question is "which technology is better?" The right question is "given what my business actually does with AI, where does the data processing need to happen?"
For a business running AI on public information, marketing content, and internal communication drafts, cloud tools are efficient and appropriate. For a business running AI on client data, proprietary processes, or regulated information, the question of where the processing happens is not optional.
The AI Capacity Assessment is designed to answer this question for your specific situation. It looks at your current AI use, identifies the workflows with the highest data sensitivity, and gives you a clear recommendation: cloud, hybrid, or on-premise, with a cost model attached. It is not a sales pitch. It is a diagnosis.
Ready to Deploy AI on Your Infrastructure?
Arkeo deploys private AI systems for businesses that are done experimenting with DIY tools. Core is live in under a week. Start with a free 30-minute AI Capacity Assessment.
Frequently Asked Questions
What does LLM stand for?
Large Language Model. It is the type of AI system that underlies most text-based AI tools, including ChatGPT, Copilot, Claude, and similar products. LLMs generate responses by predicting what text should follow a given input, based on patterns learned during training.
Is an on-premise LLM the same as self-hosted AI?
Yes. The terms are used interchangeably. "On-premise LLM" and "self-hosted AI" both refer to AI models running on infrastructure you control rather than on a cloud vendor's servers.
Do I need a data scientist to run an on-premise LLM?
Not with a managed deployment. Arkeo handles model selection, infrastructure, configuration, and ongoing operations. Business owners and their teams interact with the outputs (drafts, summaries, alerts) not the technical infrastructure.
How much does an on-premise LLM cost to run?
With Arkeo's managed deployment, Core starts at $6,500 activation plus $1,500 per month. For a full breakdown of what each tier includes and what it costs over year one, see Private AI for Business: What It Actually Costs, or book a free AI Capacity Assessment for a cost model tied to your specific workflows.
How does an on-premise LLM compare to buying an enterprise AI tool?
Enterprise AI tools (Copilot, Salesforce Einstein, and similar) run on the vendor's infrastructure. Your data is processed by them. They are easier to set up but create the same data exposure as consumer cloud AI. An on-premise LLM runs in your environment and can be configured specifically for your workflows. The tradeoff is higher initial investment for greater control and customisation.
What open-source models are used for on-premise deployment?
Arkeo selects models based on the specific use case, typically from the Llama or Mistral model families, with configuration and fine-tuning specific to your business. The model choice is part of the deployment, not a decision you need to make independently.
How long does it take to deploy an on-premise LLM?
Core is live in under one week. Connected (with CRM, email, and calendar integrations) takes 30 to 45 days. Orchestrated (multi-agent, cross-department) takes 60 to 90 days.
An on-premise LLM is not the right answer for every business. It is the right answer for businesses where the data going into the AI has real value, real sensitivity, or real compliance exposure. If you are not sure which category your business falls into, the AI Capacity Assessment will tell you clearly, with a recommendation and a cost model. No obligation before that conversation.