Category
Build an AI Readiness Framework
Last updated: June 2026
If you run a $10M to $200M company and your board has just asked for an AI plan, the worst answer you can give next quarter is a 40-slide deck without a readiness score behind it. The cost of skipping the diagnosis shows up twelve months from now as a stalled pilot, a budget cut to next year's AI line item, and a polite question from the CFO about who picked the workflow that did not ship. In this guide, you will get the exact framework Arkeo uses on engagements: six named dimensions, a 1 to 5 scoring rubric, a worked example, and the go, fix-first, or no-go rule so you can adopt the framework, run it on your own workflows, and walk into the next board meeting with a credible diagnosis instead of a hope.
According to the Stanford HAI 2025 AI Index, 78% of organizations reported using AI in 2024, up from 55% in 2023, the largest year-over-year jump in the Index's history. Using AI is now the norm. Operating it is not. Arkeo has spent the last three years deploying agents on its own operations and on mid-market client engagements, and the failure pattern that repeats is never model quality. The data is not clean, the workflow is not mapped, the approval rules are not written, and the company is shipping a pilot when it should have been running a framework against the workflow. The fastest fix is a framework named, scored, and signed off by the same operators who own the workflow.
Quick Answer
• What it is: An AI readiness framework is a named set of dimensions, a scoring rubric, and a decision rule you apply to one workflow at a time to decide whether to build, fix-first, or stop.
• The six dimensions: Data, Systems, Workflow, Governance, People, and Operating Discipline.
• The rubric: Score each dimension 1 to 5 against the named criteria; a workflow ships only if every dimension is ≥ 3 and no single dimension is < 2.
• Why it matters: Without the framework, mid-market AI spend lands in the 74% value-gap zone BCG measured in October 2024.
• Next step: Book a free AI Assessment and Arkeo will audit your workflows to see if you are ready for custom agents.
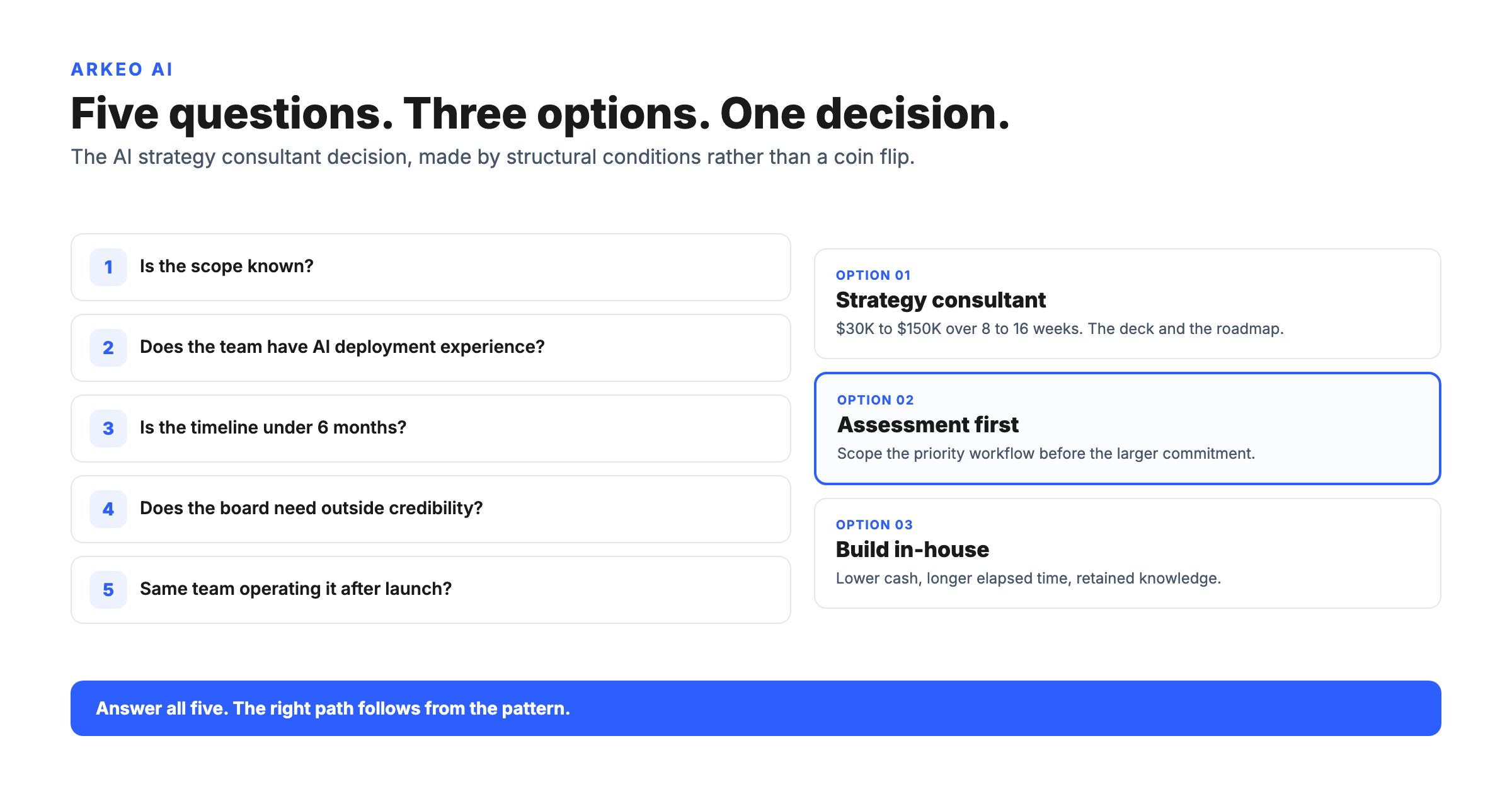
Why does building a framework matter more than running a one-off audit?
An AI readiness framework is the named, repeatable artifact your company uses to decide whether a workflow is ready for a custom agent, scored against fixed dimensions, with a written decision rule. An audit produces a verdict. A framework produces a verdict and a way to re-run the verdict next quarter against the next workflow without re-hiring a consultant. The framework is what survives after the consultant leaves and the slide deck closes. Most mid-market companies skip the framework, buy the audit, and lose the institutional memory the moment the engagement ends.
BCG research published in October 2024 (1,000+ CxOs across 59 countries) put a number on the cost of skipping it: 74% of companies struggle to achieve and scale value from AI, and only 4% have built cutting-edge AI capabilities that consistently generate significant value. The Deloitte State of Generative AI Wave 4 survey of 2,773 C-suite and director-level leaders across 14 countries reported more than two-thirds of enterprises expect 30% or fewer of their GenAI experiments to be fully scaled within the next three to six months. The companies that beat those distributions are not buying better models. They are running a framework that decides which workflows are ready and which ones are not, before any money is committed.
The framework is the institutional memory. The audit is one application of it.
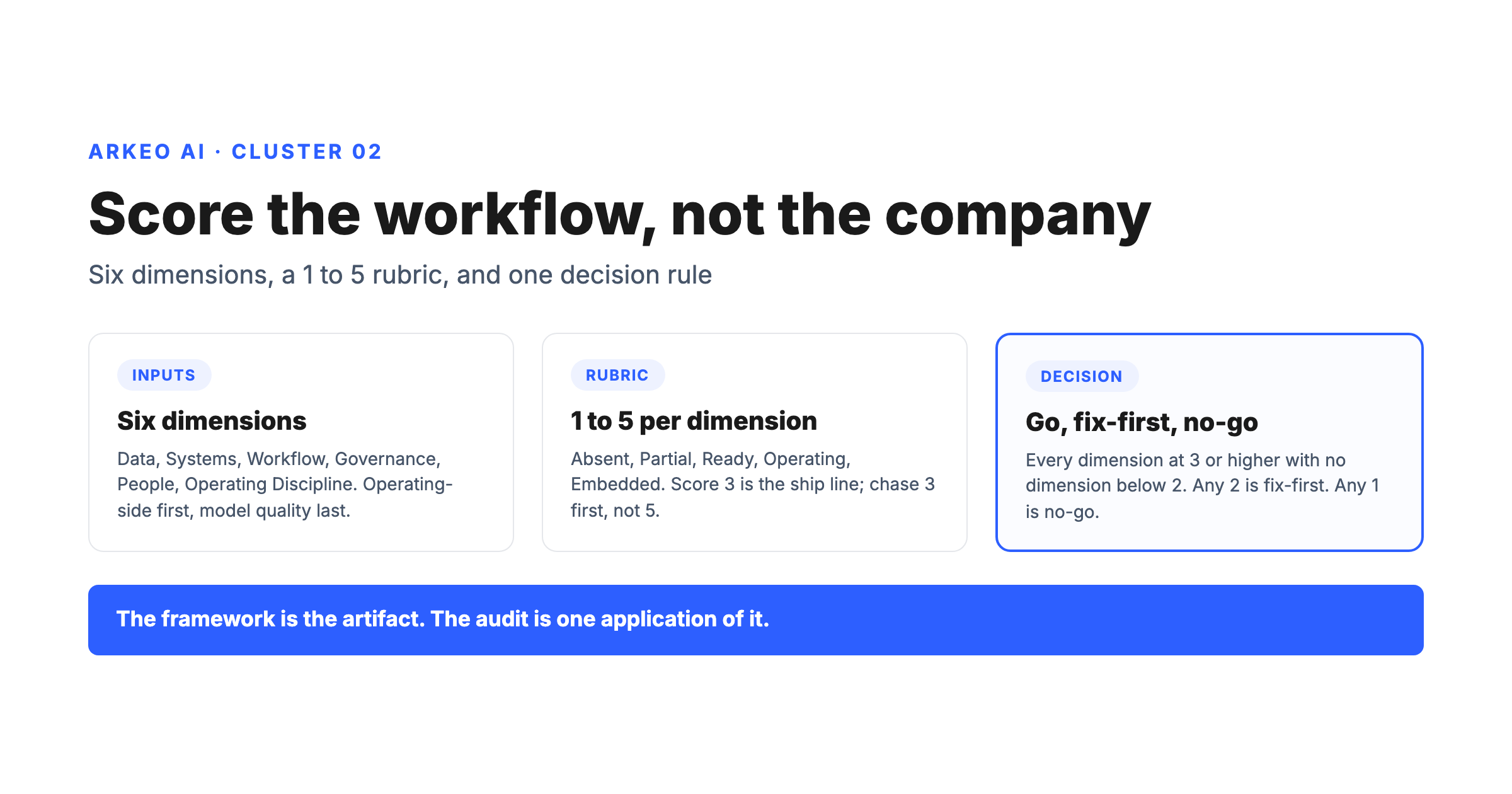
What are the six dimensions of an AI readiness framework?
The framework below is the one Arkeo runs on its own builds and on client engagements. The six dimensions are deliberately operating-discipline first and model-quality last, because in three years of shipping agents the failure modes have come from the operating side every single time. Pull the framework into a one-page artifact, name it inside your company ("the X Readiness Framework"), and apply it to one workflow at a time.
SIX DIMENSIONS
Operating-side first, model quality last
Score each workflow against the same six. Let the scores do the deciding.
DIMENSION 01
Data
Is the data the agent needs captured digitally, reachable, current, deduplicated, and labeled? Inspection notes in a notebook score zero until they hit a system. A 100-row sample from each source is the only honest way to score this.
DIMENSION 02
Systems
Can the agent reach the ERP, CRM, ticketing system, and approval queue where decisions get made? A CSV emailed twice a day is not an integration. APIs, webhooks, and event streams are.
DIMENSION 03
Workflow
Is the current workflow mapped end to end on a single page, with decision points, dollar thresholds, exceptions, and the people who currently own each step? Most are not. An agent cannot automate what only lives in one senior person's head.
DIMENSION 04
Governance
Where does the agent need a human signature, what logs does it write, and what regulated fields does it touch? The NIST AI Risk Management Framework four functions (Govern, Map, Measure, Manage) map cleanly onto this dimension.
DIMENSION 05
People
Does a named operator own the agent the day after it ships, and is the team that will use it bought in? The IBM IBV CEO Study of 2,000 CEOs across 33 countries flagged lack of expertise as the top barrier to AI innovation; 31% of the workforce will need reskilling within three years.
DIMENSION 06
Operating Discipline
Is there an on-call schedule, a runbook, a quarterly review, and a row on the operating P&L for the agent? This is the dimension that distinguishes a deployed agent from a shipped one. Arkeo has been running real companies for 25 years before deploying AI on top of them, which is why this dimension sits at the end and never gets cut.
Six dimensions, deliberately small. More dimensions produce frameworks nobody runs.
How do you score each dimension on a 1 to 5 scale?
Each dimension gets a 1 to 5 score against a fixed rubric. The rubric is written in operator language so a CFO, a COO, and a VP of Engineering can score the same workflow and land within one point of each other. If the three roles do not converge, the framework has been written badly; re-write it until they do.
SCORE 01
Absent
The dimension does not exist for this workflow. Data is on paper, the system has no API, the workflow is in one person's head, governance is undocumented, no owner exists.
SCORE 02
Partial
The dimension partially exists, but with gaps that would break an agent. Some data is digital, the system exports a CSV, the workflow is documented in slide deck form, an owner is named but part-time.
SCORE 03
Ready — the ship line
The dimension is present in production-grade form. Data is in a database, the system has an API, the workflow is mapped, governance is written, an owner is named and has time allocated. This is the ship line.
SCORE 04
Operating
The dimension is in steady operation with monitoring. The data pipeline is observed, the integration alerts on failure, the workflow has a runbook, governance has audit logs, the owner has an on-call schedule.
SCORE 05
Embedded
The dimension is a routine business capability. New workflows can be added without rewriting it. This is the long-run target, not the prerequisite to ship.
The temptation is to chase 5s. Resist it. Stage 3 is the line between using AI and operating AI, and chasing 5s before any workflow is at 3 is how mid-market AI budgets disappear into platform fees with nothing in production.
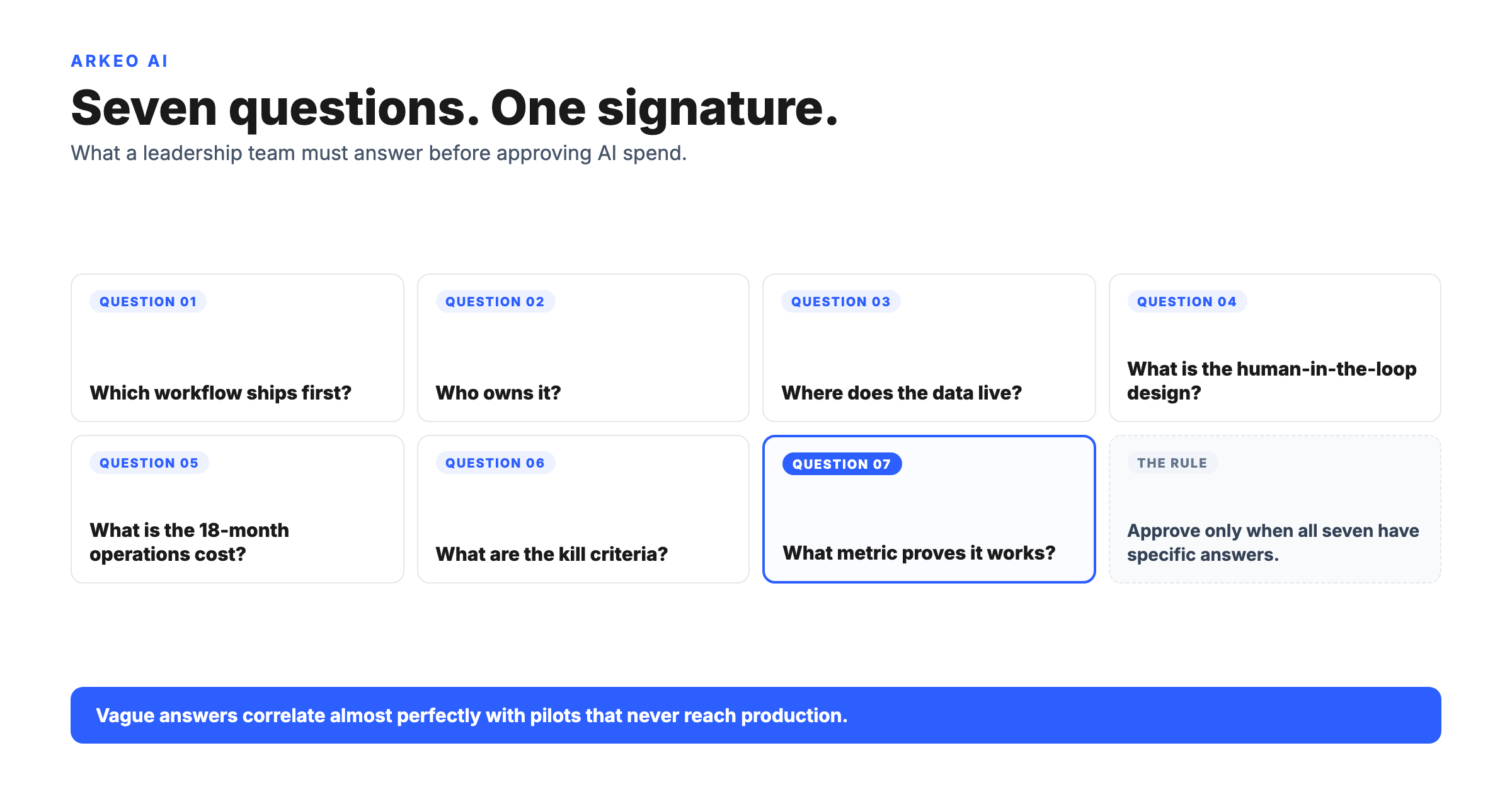
What is the go, fix-first, or no-go decision rule?
The rule is one sentence, deliberately strict, and you should not weaken it without writing down why.
Ship the workflow only if every dimension scores ≥ 3 and no single dimension scores < 2. Any 2 is fix-first. Any 1 is no-go until the gap is closed.
That rule is the entire decision system. It looks blunt because it is. The reason most mid-market AI pilots stall is that operators score four dimensions at 3 or 4, see one dimension at 2 (almost always Workflow, Governance, or People), and ship anyway because the model demo looked good. The agent ships, the missing dimension surfaces in week six, and the project is rebranded as a pilot. The strict rule prevents that.
For a fix-first workflow, the framework also names the shortest path to score 3 on the failing dimension. A score-2 Data dimension might need a 4-week capture project. A score-2 People dimension might need an owner re-assigned. The framework holds the workflow in queue, schedules the fix, and re-scores before the build starts. Most of the value the framework produces is in this fix-first lane, because the no-go list is short and the go list is small. The fix-first list is where the company actually changes.
See which of your workflows score ≥ 3 todayThe free AI Assessment runs this framework against one of your workflows end-to-end and tells you whether it is go, fix-first, or no-go. No pitch deck.
Book Your Free AI Assessment →
How does the framework apply to a real workflow?
Picture a 180-person specialty distributor running a quoting workflow. RFQs arrive by email, a senior sales engineer parses them, looks up stock and lead time in the ERP, writes a quote in a spreadsheet, gets it signed off by the sales manager when the value exceeds $10K, and emails the quote back. The team wants an AI agent to compress this from days to hours.
Score the six dimensions:
WORKED EXAMPLE · QUOTING WORKFLOW
One dimension at 2 means fix-first, not no-go
A 180-person distributor scores six dimensions before building a quote-drafting agent.
DATA · SCORE 3
Ready
RFQ emails are captured in the shared inbox; ERP stock and lead-time data is in the database. Ready, with a parsing step for the inbound RFQs.
SYSTEMS · SCORE 3
Ready
The ERP exposes a REST API; the email system has an IMAP feed and a webhook. Both are reachable for the agent.
WORKFLOW · SCORE 2
Fix-first
The end-to-end map exists in the sales engineer's head and in a 2019 Visio file nobody trusts. Fix-first: spend a week mapping the live workflow before any build.
GOVERNANCE · SCORE 3
Ready
The $10K approval rule is written; the sign-off lives in email. The agent can route to the same approver via Slack.
PEOPLE · SCORE 4
Operating
A sales operations lead is named owner, has 25% of their week allocated, and is already running the existing workflow's metrics.
OPERATING DISCIPLINE · SCORE 3
Ready
A morning check, a weekly metric, and a quarterly review are agreed. Will appear on the sales operating P&L the quarter after launch.
Verdict: fix-first. Close the workflow map, then ship. 6 to 10 weeks to production.
One dimension at 2 (Workflow). The rule says fix-first. A scoped four-day mapping sprint moves Workflow to 3, after which the build clears. Without the framework, the team would have skipped the workflow map, built the agent on assumed rules, and discovered the exceptions in production. With the framework, the missing map is named, scoped, and closed before any code runs. A scoped single-workflow agent like this typically runs $15K to $40K and reaches production in 6 to 10 weeks, 8 to 12 weeks when the deployment is private or on-premise, with the first quick win inside 30 to 90 days. Those are operator ranges from Arkeo's own builds.
What are the common failure modes when running this framework?
Four recur every quarter. Watch for them and the framework keeps its teeth.
FAILURE MODES
Four ways the framework loses its teeth
Each is a discipline failure, not a model failure. Name it before it happens and the framework keeps producing verdicts.
01
Grading on a curve
A team that wants to ship rounds 2s up to 3s. The fix: have one outside reviewer score every workflow on the same day as the internal team, and reconcile in writing before any build is approved.
02
Skipping People and Operating Discipline
These two dimensions are the most uncomfortable because they expose org chart gaps. They are also the dimensions that most often kill the agent in week eight. Score them honestly even when the result hurts.
03
Confusing shadow AI with readiness
Heavy ChatGPT use in a department is shadow AI, not readiness. IBM's 2025 Cost of a Data Breach report found organizations with high shadow-AI usage incur an extra $670,000 per breach and 97% of AI-related breaches lacked proper access controls.
04
Scoring the company, not the workflow
A company-wide score is a vanity metric. The framework only produces useful answers per workflow. Treat company-wide readiness as the distribution of workflow scores, never an average.
Most internet readiness frameworks produce a maturity score. The framework above produces a verdict. Verdicts are what ship.
Want a walk-through against your own workflow? Book the free AI Assessment at arkeoai.com/ai-assessment and Arkeo will run the framework on one of your workflows end to end. We use what we sell: the same framework runs on Arkeo's own internal agents under the Assess, Deploy, Manage methodology, including the on-premise and private AI deployments where the data never leaves the building.
How does this framework relate to ai readiness, the maturity model, and AI strategy?
This framework sits inside the broader ai readiness work. The framework is the artifact. The ai maturity model is the company-wide view (Ad Hoc, Aware, Active, Operating, Embedded) that comes out of running the framework across many workflows. The ai readiness assessment is the engagement that runs the framework on a defined scope. The ai audit is the data-side deep dive that feeds the Data and Governance dimensions.
Readiness owns the current state. AI strategy owns the future state: the sequencing, the 30-day quick wins, the 90-day agent build, the 12-month architecture. If you have a strategy without a readiness framework, the strategy is fiction. If you have a readiness framework without a strategy, you have a diagnosis but no plan. Both are required, and the right reading order is framework first, strategy second, ROI math third.
Audit your workflows in 60 minutesArkeo's free AI Assessment runs the six-dimension framework against one of your workflows and gives you a go, fix-first, or no-go decision you can take to the board.
Book Your Free AI Assessment →