Category
How to Measure Your AI Readiness Score

Last updated: June 2026
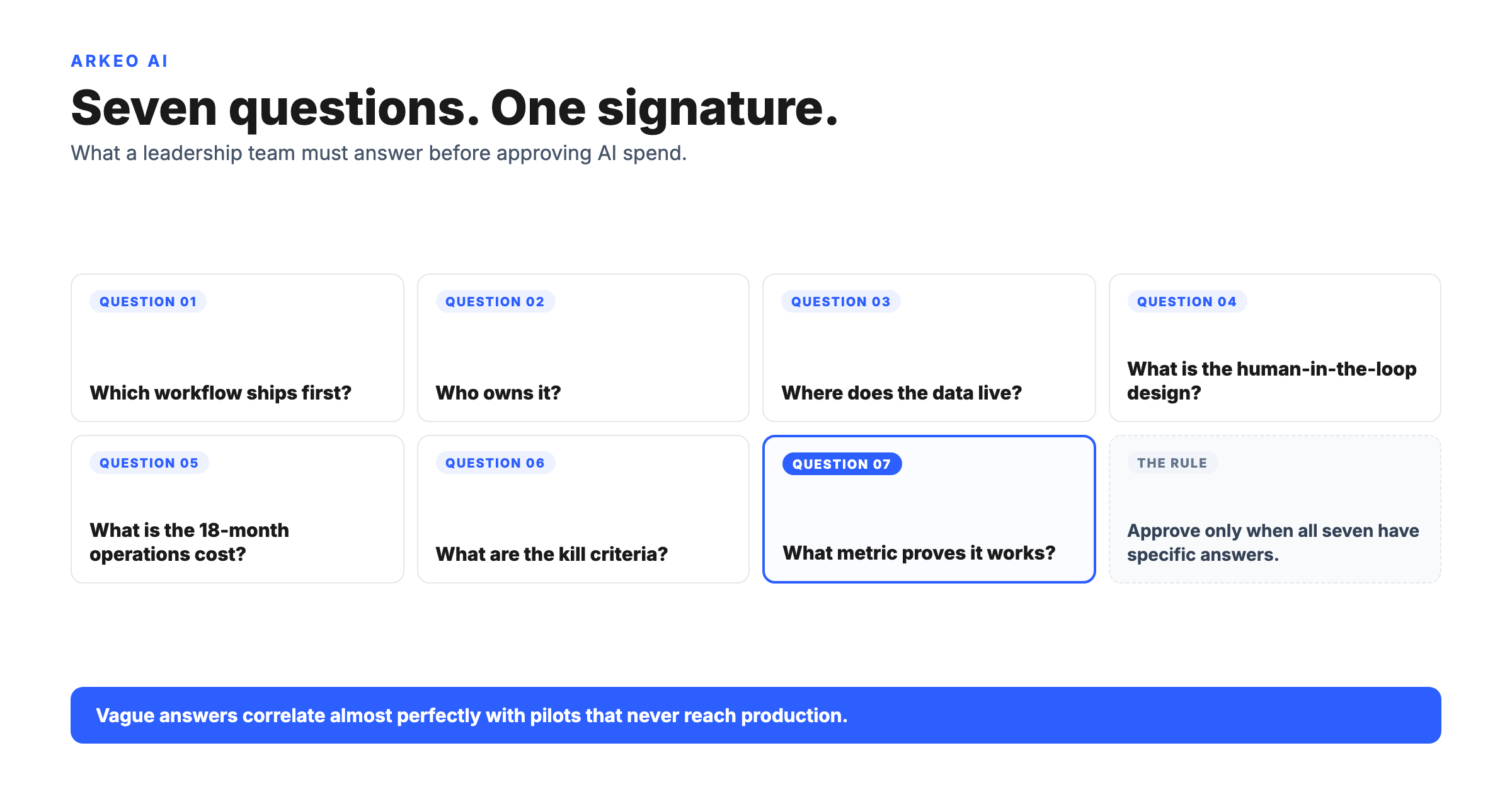
If you run a $10M to $200M company and your board has asked for an AI readiness score before approving the next AI line item, the wrong answer surfaces twelve months later as a stalled pilot, a written-off six-figure build, and a budget that gets reallocated to anything that is not AI. The number on the slide is meaningless unless the methodology behind it is workload-specific, weighted, and tied to a go, fix-first, or no-go decision the operator can defend in writing. In this guide, you will get the six-dimension scoring rubric Arkeo uses across three years of deploying agents (including its own), the weights, and the thresholds for go, fix-first, or no-go, so you can hand the board a score with an action attached.
The failure mode that repeats across those engagements is not model quality. It is the absence of a real score. Companies present a four-color heatmap to the board, the board approves a budget, and the build hits the same data, integration, and ownership walls that a real readiness score would have flagged in week one. According to the Stanford HAI 2025 AI Index, 78% of organizations reported using AI in 2024, up from 55% in 2023, the largest year-over-year jump in the Index's history. Adoption is now the floor. Whether your specific workflow is ready to put a custom agent into production is the question a score has to answer.
Quick Answer
• What it is: An AI readiness score is a weighted, workload-specific 0 to 100 number that grades a candidate workflow against six dimensions: data availability, data quality, system integration, workflow clarity, governance, and ownership.
• How you measure it: Score each dimension 1 to 5, multiply by the weight, sum to 100. A workload at 75 or higher with no single dimension below 3 is green-lit for a custom agent build.
• Cost of skipping it: Pilots that stall at integration, breaches tied to ungoverned shadow AI ($670,000 added breach cost per IBM 2025), and budget cuts after one bad quarter.
• Why it matters: A real score replaces vibes with a go, fix-first, or no-go decision the CFO and the COO can both sign.
• Next step: Book a free AI Assessment and Arkeo will audit one of your workflows and score it against the same rubric.
SIX DIMENSIONS
Score 1–5 per dimension. Weights sum to 100.
Score the workload against operating anchors, not adjectives.
25 PTS · DATA AVAILABILITY
Captured + reachable
Digital, API or export accessible. PDFs in a shared drive score 1 until parsed.
20 PTS · DATA QUALITY
Clean + labeled
100-row sample probe. Completeness, correctness, deduplication, labeling.
20 PTS · INTEGRATION
Reaches the decision
ERP, CRM, ticketing, approval queue. CSV exports score 2, not 4.
15 PTS · WORKFLOW CLARITY
Written down
Inputs, outputs, decisions, exceptions. Tribal knowledge scores 2.
10 PTS · GOVERNANCE
Approvals mapped
Human signature points named. NIST Govern function applied.
10 PTS · OWNERSHIP
Named operator
Owns the agent the day after it ships. No consultant placeholder.
Composite is the headline. The minimum dimension is the asterisk that decides whether the headline is true.
What is an AI readiness score and why does the methodology matter?
An AI readiness score is a weighted, workload-specific 0 to 100 number that grades a candidate workflow against six operating dimensions and resolves to a go, fix-first, or no-go decision before any custom agent build begins. The methodology matters because two scores can read the same on the slide and mean entirely different things underneath. A 70 with a 2 in data quality is not the same as a 70 with a 4 across the board, and a build contract signed on the first 70 is how mid-market companies end up paying the breach tax instead of the build cost.
The reason a score has to be workload-specific is that ai readiness is not a company property. A 200-person specialty manufacturer can be ready for an off-the-shelf copilot in marketing, fix-first for a quoting agent in sales engineering, and not ready at all for an autonomous finance agent, all on the same Monday morning. Score the workload, not the company. The company-level number is the distribution of workload scores, not the average.
Deloitte's State of Generative AI Wave 4 survey of 2,773 C-suite and director-level leaders across 14 countries found that more than two-thirds of enterprise respondents expect 30% or fewer of their GenAI experiments to be fully scaled within the next three to six months. That gap, between using AI and operating AI, is exactly the gap a real readiness score measures. BCG research published in October 2024 put a number on the same pattern: 74% of companies struggle to achieve and scale value from AI, and only 4% have built cutting-edge AI capabilities that consistently generate significant value. A defensible score is the first artifact that separates the 4% from everyone else.
What are the six dimensions you score?
The rubric Arkeo uses on engagements scores each workload candidate against six dimensions. Each one scores 1 to 5, against the operating bar a custom agent will actually have to clear in production. Treat any single 1 as a hard no-go for that workload, and any 2 as fix-first.
DIMENSION 1 · WEIGHT 25
Data availability
Is the data the agent needs captured digitally in a system that can be reached via API or export? PDFs in a shared drive score 1 until parsed. Inspection notes in a tradesperson's notebook score 0. Capture comes before cleaning.
DIMENSION 2 · WEIGHT 20
Data quality
Pull a 100-row sample. Score completeness, correctness, deduplication, and labeling. An agent that runs on dirty CRM contacts will scale your existing bad outcomes faster, not better.
DIMENSION 3 · WEIGHT 20
System integration
Can the agent reach the ERP, CRM, ticketing system, and approval queue where decisions get made? If the answer is “only via a CSV emailed twice a day,” the agent will live as a suggestion box.
DIMENSION 4 · WEIGHT 15
Workflow clarity
Has the current workflow been written down with inputs, outputs, decision points, and exception paths? An agent cannot automate a process that lives only in the head of one senior person about to retire.
DIMENSION 5 · WEIGHT 10
Governance and approvals
Where does the agent need a human signature? An invoice over $5K, a customer refund, a contract clause. The NIST AI Risk Management Framework calls this the Govern function. Map approval points before the build.
DIMENSION 6 · WEIGHT 10
Ownership and culture
Does a named operator own the agent the day after it ships? If the answer is the consultant, the agent will die in 90 days. The IBM IBV CEO Study cites lack of expertise as the top barrier to AI innovation.
Most readiness frameworks stop at three dimensions: data, infrastructure, culture. That is the false-belief most boards inherit, and it is wrong. Three dimensions hide the integration cliff and the approvals trap inside the “culture” bucket, and the workload ships anyway because nobody scored them separately. Six dimensions are the minimum that exposes every place a build actually fails. Skipping any one of them is how 13% of breached organizations end up reporting a breach of an AI model or application, per IBM's 2025 Cost of a Data Breach report: 97% of those AI-related breaches lacked proper AI access controls.
Score your workflow with ArkeoLet's audit your workflows to see if you're ready for custom agents. The free AI Assessment runs the same six-dimension rubric on one of your candidate workflows and returns a go, fix-first, or no-go decision.
Book Your Free AI Assessment →
How do you score each dimension from 1 to 5?
Each dimension uses the same 1 to 5 anchor scale so the score is comparable across workloads and across companies. The anchors are operating bars, not adjectives. The score the workload earns is the score the agent will inherit on day one of production.
1 · Absent
The capability does not exist. Data is in heads or paper. No integration. No written workflow. No owner. Treat as automatic no-go for this workload.
2 · Ad hoc
The capability exists in one place, undocumented, unmonitored. CSV exports. Tribal knowledge. One person knows. Fix-first before any build proceeds.
3 · Functional
Documented, reachable, owned by a named person, good enough for a scoped pilot. This is the minimum bar to ship a custom agent into the workflow.
4 · Operating
API-accessible, monitored, audited, owned by a team. The workload can carry an agent in production without daily fire-fighting.
5 · Embedded
Native to an AI operating system. Scoped permissions, audit logs, on-call ownership, lifecycle managed. The agent can scale across departments without rework.
Score conservatively. The scoring instinct that costs companies money is to round up on dimensions the team feels good about and round down on the ones they do not. Force every score against the anchor, not against the room. The score is a contract with the build, not a status report.
How do you turn six scores into one weighted readiness score?
Multiply each dimension score by its weight, sum to 100. The weights are not democratic. Data availability and quality together carry 45 points because the agent that cannot reach clean data fails on day one, regardless of how well-governed it is. Integration carries 20 because an isolated agent has no operating effect. Governance and ownership combined carry 20 because an agent without approvals or an owner becomes a liability before it becomes a return.
WORKED EXAMPLES
Three workloads, three decisions
Same rubric, same weights, different operating evidence.
WORKLOAD 01
A quoting workflow
Data 4 × 25 = 20. Quality 3 × 20 = 12. Integration 3 × 20 = 12. Workflow 4 × 15 = 12. Governance 3 × 10 = 6. Ownership 3 × 10 = 6. Total: 68. Yellow zone. Fix integration before build.
WORKLOAD 02
An AP automation workflow
Data 2 × 25 = 10. Quality 2 × 20 = 8. Integration 4 × 20 = 16. Workflow 4 × 15 = 12. Governance 4 × 10 = 8. Ownership 3 × 10 = 6. Total: 60. Red zone. Two 2s. No-go until invoice capture is fixed.
WORKLOAD 03
A customer support triage workflow
Data 4 × 25 = 20. Quality 4 × 20 = 16. Integration 4 × 20 = 16. Workflow 4 × 15 = 12. Governance 4 × 10 = 8. Ownership 4 × 10 = 8. Total: 80. Green zone. Build approved.
A high composite hides a low dimension. Always read the score with the lowest dimension printed next to it.
One blunt truth before any score becomes a green light: a high composite hides a low dimension. Always read the score with the lowest dimension printed next to it. A 75 with a 2 in governance is a 75 with a regulatory incident waiting to be scheduled. The weighted total is the headline; the minimum dimension is the asterisk that decides whether the headline is true.
What thresholds decide go, fix-first, or no-go?

The composite score has three bands, and the minimum dimension overrides the composite. Read the table left to right. If the composite says go but a dimension says fix-first, the workload is fix-first. The minimum dimension always wins, because the agent will hit the weakest dimension on day one.
DECISION BANDS
Three zones. Minimum dimension overrides composite.
Composite says the headline. The lowest dimension decides whether the headline is true.
GREEN ZONE
75–100 and min dimension ≥ 3
Go. Custom agent build is approved. Move to ROI prioritization, scope a single workflow, and ship in 6 to 10 weeks (8 to 12 weeks for private or on-premise). This is Arkeo's Deploy phase.
YELLOW ZONE
60–74 or any dimension = 2
Fix-first. Build is paused. Take the lowest-scoring dimension, close the gap in 30 to 60 days, re-score, then proceed. Off-the-shelf copilots are fine here; custom agents are not.
RED ZONE
< 60 or any dimension = 1
No-go. The workload is not a candidate for a custom agent. Pick a different workflow. Spending the build budget here is how the 74% value gap that BCG measured gets made.
A one-line decision the CFO and the COO can both sign before any build budget is committed.
The honest mid-market reality: most candidate workflows land in yellow on first score. That is not a failure of the workload. It is the audit doing its job. The fix-first work that follows, capturing data that was never captured, exposing an integration, naming an owner, is the operating-discipline work that turns the score green inside one quarter. Arkeo has been in business for 25 years operating real companies before deploying AI agents on top of them, which is why the readiness work looks like operations work and the score is graded on operating evidence, not aspiration.
Want a walk-through against your own workflow? Book a free AI Assessment and Arkeo will run this rubric on your data, score the workflow live, and hand you the fix-first or go decision the same week.
How does the score feed the rest of the AI program?
The readiness score is the input to three downstream decisions, and the order matters. Readiness owns the current state. Strategy owns the future state. ROI owns the financial justification. Scoring without sequencing is how a 78 readiness score turns into a slide deck instead of a deployed agent.
SCORE TO PROGRAM
Four steps from score to shipped agent
Readiness owns current state. Strategy owns future state. ROI owns the justification. Sequence matters.
STEP 01
Score the workload
Run the six-dimension rubric per candidate workflow. Output: composite score, minimum dimension, go/fix/no-go decision.
STEP 02
Sequence the strategy
Pass green-zone workloads to the 30/90/12-month roadmap. Pass yellow-zone workloads to the 30 to 60-day fix-first queue. Drop red-zone workloads.
STEP 03
Justify the spend
Run ROI math on the green-zone workloads. A scoped single-workflow agent runs $15K to $40K and 6 to 10 weeks. The first quick win lands in 30 to 90 days.
STEP 04
Deploy and manage
Build the agent, deploy into the workflow, and operate it under the Manage phase. Re-score the workload after one quarter in production.
Scoring without sequencing turns a 78 readiness score into a slide deck instead of a deployed agent.
Those costs are Arkeo's own build experience across three years of deploying agents on its own operations and on mid-market client engagements, not sourced benchmarks. Off-the-shelf copilots like Microsoft 365 Copilot or ChatGPT Enterprise are roughly $20 to $30 per user per month and live in days, which is why fix-first workloads can carry a copilot while the score climbs to green.
What are the common failure modes when scoring?
Four mistakes turn a useful score into a misleading one. Watch for all four when reviewing a score on the way to the board.
FAILURE MODES
Four mistakes that turn a score into a misleading one
Watch for all four when reviewing a score on the way to the board.
FAILURE 01
Scoring the company, not the workload
A single company-wide score is the most common mistake. Score each workload. Roll up only as a distribution, not an average.
FAILURE 02
Letting the team self-score in a room
Self-scores skew high. Anchor every dimension to a 100-row sample, an API contract, or a written workflow document. Evidence over opinion.
FAILURE 03
Ignoring the minimum dimension
A 78 composite with a 2 in data quality is not green. The agent hits the 2 on day one. Always read the score with the minimum dimension printed next to it.
FAILURE 04
Skipping the re-score after fix-first
Fix-first work has to be verified. Re-score the workload after the fix, with new evidence, before approving the build. No re-score, no build.
Score once and treat the score as permanent and the agent inherits a system that no longer exists.
One more pattern that costs companies money: scoring once and treating the score as permanent. Workloads change. The CRM integration the score depended on gets deprecated, the named owner leaves, the data pipeline drifts. Re-score every workload in production once per quarter as part of the Manage phase. Arkeo runs its own agents under this cadence: we use what we sell.
Get a workload-level readiness scoreLet's audit your workflows to see if you're ready for custom agents. The free AI Assessment scores one of yours against the same six-dimension rubric and gives you a go, fix-first, or no-go decision you can take to the board.
Book Your Free AI Assessment →