Category
Choosing a Self-Hosted AI Model for Business
Last updated: May 2026
You keep hearing that you can run your own AI now, on your own hardware, with your data never leaving the building. The pitch is clean. The decision is not. The moment you start shopping, the conversation collapses into a benchmark argument: this model beats that model by a point and a half on some leaderboard. That framing is a trap. Arkeo AI has spent three years deploying production AI agents for operating businesses, and the model is rarely the thing that decides whether a self-hosted deployment works.
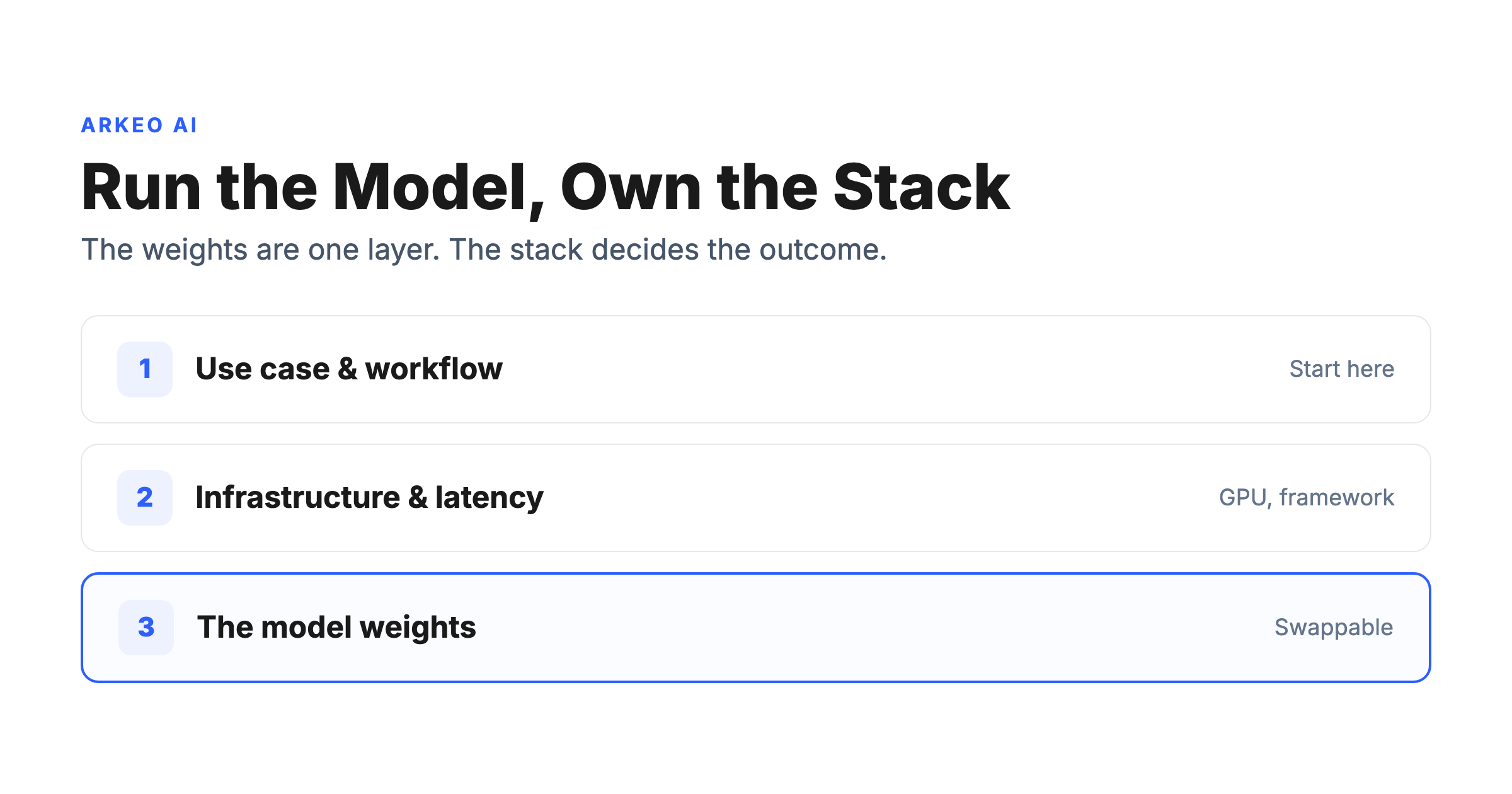
A self-hosted AI model is a set of trained model weights you deploy and run on infrastructure you own or control, whether that is a server in your building, a rented instance dedicated to you, or a workstation under a desk, rather than a model you reach through a third party's API. That definition is doing a lot of work, because it means the model is one layer in a stack you now own. The weights are the part everyone talks about. The stack is the part that decides your outcome. If you want a clear-eyed read on whether self-hosting fits your operation at all, a free AI Assessment is the fastest way to find out before you spend a dollar on hardware.
Quick Answer
• What it is: model weights you run on infrastructure you own or control, not a third party's API.
• What model choice changes: capability ceiling, licensing rights, and hardware cost, not whether the workflow works.
• What matters more: use-case fit, latency, infrastructure burden, and privacy posture.
• Why it matters: the right model on the wrong stack is a non-working system; the right stack tolerates a swappable model.
What Is a Self-Hosted AI Model, and Why Is Everyone Talking About It?
The reason self-hosting went mainstream is volume. Meta's open-weight Llama family crossed one billion total downloads in March 2025, and reached 1.2 billion by LlamaCon a month later. Hugging Face, the main hub for these models, now hosts more than two million public models. Self-hosting stopped being a research-lab exercise and became something a real business can actually do.
The quality argument also got harder to dismiss. According to Stanford HAI's 2025 AI Index, the performance gap between the best closed model and the best open-weight model narrowed from 8.04% in January 2024 to 1.70% by February 2025, nearly an 80% reduction in a single year. For most business workloads, that gap is now small enough that capability is no longer the deciding factor. Which is exactly why obsessing over the model is the wrong instinct.
Why Does Model Choice Matter at All?
It does matter, in three specific ways. First, the capability ceiling: a 7-billion-parameter model and a 70-billion-parameter model are not interchangeable on hard reasoning or long-document work. Second, licensing, which most buyers never read. Third, hardware cost, because model size dictates the GPU you need.
Licensing is where teams get burned. "Open weight" and "open source" are not the same thing. Open-weight models publish the trained parameters; open-source models also publish the training code and data. Most models you would self-host, including Llama, Mistral, and others, are open-weight, and their licenses vary a lot. The Meta Llama license is not an OSI-approved open-source license: it permits commercial use for most companies but caps free commercial use at 700 million monthly active users and bars using Llama outputs to train competing models. By contrast, Mistral released Mistral Large 3 in December 2025 under Apache 2.0, a standard permissive license with no such strings. If your compliance team needs a clean license, that difference matters more than a benchmark point. Most businesses think picking a model is a quality decision. It is at least as much a legal one.
If Not the Model, Then What Should a Business Actually Evaluate?
Here is the blunt truth a vendor demo will not show you: the right model on the wrong stack is a system that does not work. Model choice is a subset of the deployment decision. The weights interact with your inference framework, quantization level, hardware, network latency, and any fine-tuning you do. Get those wrong and the best model on the leaderboard still fails in production. Four things deserve more of your attention than the model name.
Use-case fit. A model that drafts internal documents well may be the wrong tool for low-latency customer chat or for parsing structured records. Start from the workflow, then ask which model serves it, not the reverse.
Latency. A self-hosted model that answers in 400 milliseconds and one that answers in four seconds are different products to the person waiting on the screen. Latency is a function of hardware and inference setup, not just the model.
Infrastructure burden. Someone has to own the GPUs, the inference server, the updates, and the 2 a.m. failures. That is real headcount or a real partner, not a download.
Privacy posture. If the reason you are self-hosting is that data cannot leave your environment, your deployment design, covering network isolation, access controls, and logging, matters more than which open model you chose.
See where AI actually fits your operation
The free AI Assessment maps your real workflows and data before anyone talks hardware or models, so you commit budget to the right layer first.
Book Your Free AI Assessment →

The genuine reasons to self-host are data residency, cost at high volume, and customization, not raw capability. And at low usage, a cloud API is usually cheaper than owning hardware. Self-hosting earns its keep when your token volume is high enough to spread the cost of a GPU across a busy, dedicated workload.
How Much Hardware Does Self-Hosting a Model Really Take?
This is where the spreadsheet gets real, because model size sets the hardware floor. A 7-billion-parameter model can run on a single consumer GPU with around 24 GB of memory. A 70-billion-parameter model needs one or more data-center GPUs. The NVIDIA H100 ships with 80 GB of HBM3 memory, which is the practical enabler for running a 70B-class model on a single card. That memory capacity, not raw speed, is the gate.

Cost-per-token is the other side of the ledger. NVIDIA reports that an H100 running an open 120B-parameter model with the vLLM framework delivers inference at roughly $0.09 per million tokens. The newer B200 reaches about $0.02 per million, roughly 4.5 times cheaper. Those numbers only become relevant once you are running enough volume to fill the hardware. Below that line, the math favors an API. This is precisely why the model question cannot be answered without the volume question first.
A Quick Self-Host Readiness Check
Before you price a single GPU, the honest filter is whether self-hosting is even the right shape for your situation. The table below is the kind of native, skimmable asset worth keeping near the top of any internal memo on this decision.
| Evaluation criterion | Lean toward self-hosting when | Lean toward an API when |
|---|---|---|
| Data residency | Data cannot legally or contractually leave your environment | Data is non-sensitive and a vendor DPA is acceptable |
| Usage volume | High, steady token volume that keeps a GPU busy | Low or spiky volume that leaves hardware idle |
| Customization | You need fine-tuning or full control of the model behavior | A general-purpose hosted model already fits |
| Operations capacity | You have, or will hire, owners for the infrastructure | No appetite to run GPUs, patching, or on-call |
What Are the Common Mistakes in Choosing a Self-Hosted AI Model?
Two failure patterns show up again and again. The first is choosing by hype: a new model tops a leaderboard, so it gets selected, regardless of whether its license permits your use or its size matches your hardware. Picture an operations lead who greenlights a 70B model for an internal helpdesk because it scored highest that week, then discovers the workflow only needed a 7B model on a single GPU, and the larger choice tripled the hardware bill for no measurable gain. That is an avoidable mistake, and it traces back to starting with the model instead of the workflow.
The second is ignoring workflow reality. Llama models have been the most-downloaded open models on Hugging Face two years running, which makes them a safe, well-supported default for many teams. But "popular" is not the same as "right for your job." A model that is excellent at general chat can still be a poor fit for a latency-sensitive or highly structured task. The download chart does not know your workflow.
This is the discipline behind how Arkeo works. We use what we sell: the same on-premise and private AI deployments we run for clients, we run ourselves, and the pattern holds: teams that map the workflow first and treat the model as swappable end up with systems that survive. The model you pick this quarter may not be the one you run next year, and a well-designed stack lets you change it without rebuilding everything.
How Do You Choose Without Overcomplicating It?
The decision is simpler than the benchmark noise suggests. Work in this order. Define the workflow and the data it touches. Decide whether the data forces self-hosting or merely allows it. Estimate volume to see if hardware can be kept busy. Then, and only then, choose a model that fits the task, the license terms, and the GPU you can justify. Founded in 2023 and built on 25 years of running real businesses, Arkeo treats this as a business decision with a technical layer, not a technical decision looking for a business case.
That ordering is the entire point. Get the stack and the use case right and the model becomes a detail you can revise. The same logic underpins the self-hosted AI agents you might eventually build on top of the model, where workflow design matters even more than the underlying weights. For the full picture of running AI inside your own walls, the self-hosted AI overview connects model choice to the broader infrastructure and governance decisions.
When the stakes get higher, think regulated data, multiple integrated systems, or real budget about to move, that is the point to bring in outside help. The free AI Assessment is the right first step to scope it. If the work warrants a deeper, paid diagnostic, the Consult is the logical next tier after that, but the assessment costs you nothing and tells you whether self-hosting is even the right path.
Decide the right layer before you buy
The free AI Assessment shows you which problems a self-hosted model actually solves for your business, so you invest in workflow and infrastructure first.
Book Your Free AI Assessment →





